 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUT: Controllable Unsupervised Text Simplification
Paper and Code
Dec 03, 2020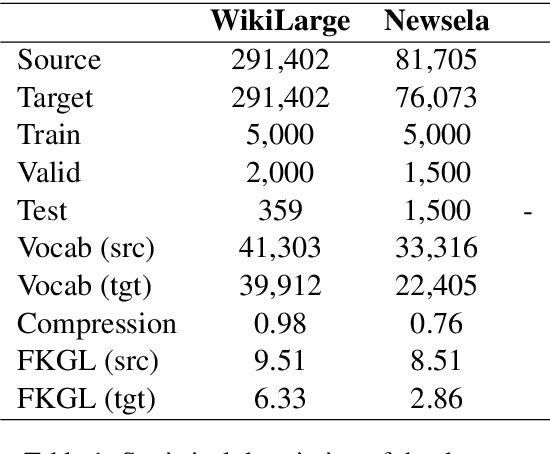
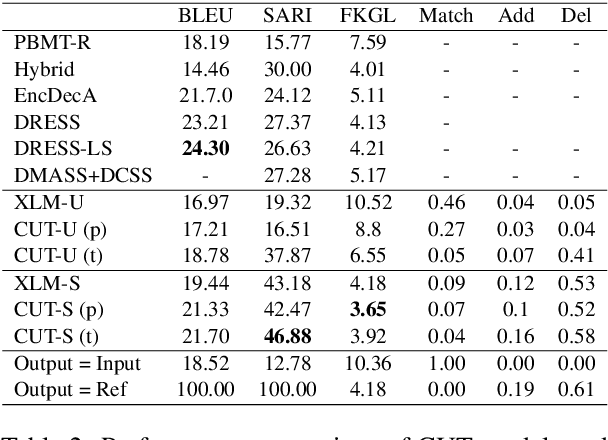

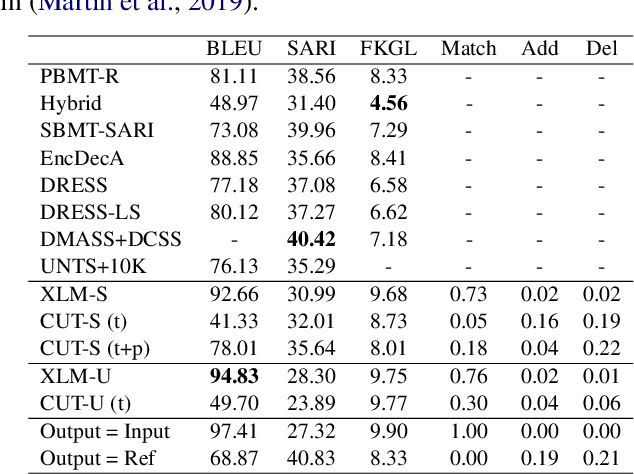
In this paper, we focus on the challenge of learning controllable text simplifications in unsupervised settings. While this problem has been previously discussed for supervised learning algorithms, the literature on the analogies in unsupervised methods is scarse. We propose two unsupervised mechanisms for controlling the output complexity of the generated texts, namely, back translation with control tokens (a learning-based approach) and simplicity-aware beam search (decoding-based approach). We show that by nudging a back-translation algorithm to understand the relative simplicity of a text in comparison to its noisy translation, the algorithm self-supervises itself to produce the output of the desired complexity. This approach achieves competitive performance on well-established benchmarks: SARI score of 46.88% and FKGL of 3.65% on the Newsela dataset.