 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCursive Multilingual Characters Recognition Based on Hard Geometric Features
Paper and Code
Apr 07, 2019


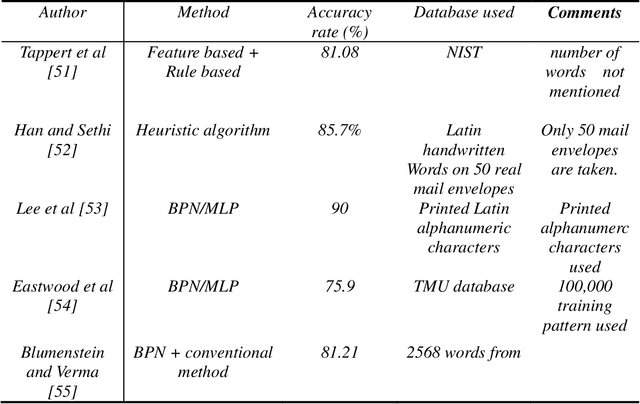
The cursive nature of multilingual characters segmentation and recognition of Arabic, Persian, Urdu languages have attracted researchers from academia and industry. However, despite several decades of research, still multilingual characters classification accuracy is not up to the mark. This paper presents an automated approach for multilingual characters segmentation and recognition. The proposed methodology explores character based on their geometric features. However, due to uncertainty and without dictionary support few characters are over-divided. To expand the productivity of the proposed methodology a BPN is prepared with countless division focuses for cursive multilingual characters. Prepared BPN separates off base portioned indicates effectively with rapid upgrade character acknowledgment precision. For reasonable examination, only benchmark dataset is utilized.