 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowd-Powered Data Mining
Paper and Code
Oct 19, 2018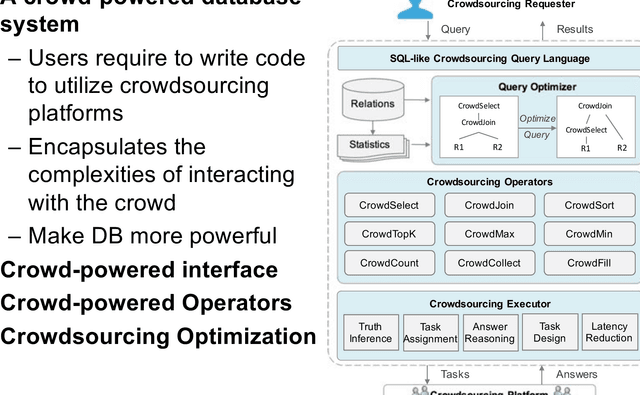

Many data mining tasks cannot be completely addressed by auto- mated processes, such as sentiment analysis and image classification. Crowdsourcing is an effective way to harness the human cognitive ability to process these machine-hard tasks. Thanks to public crowdsourcing platforms, e.g., Amazon Mechanical Turk and Crowd- Flower, we can easily involve hundreds of thousands of ordinary workers (i.e., the crowd) to address these machine-hard tasks. In this tutorial, we will survey and synthesize a wide spectrum of existing studies on crowd-powered data mining. We first give an overview of crowdsourcing, and then summarize the fundamental techniques, including quality control, cost control, and latency control, which must be considered in crowdsourced data mining. Next we review crowd-powered data mining operations, including classification, clustering, pattern mining, machine learning using the crowd (including deep learning, transfer learning and semi-supervised learning) and knowledge discovery. Finally, we provide the emerging challenges in crowdsourced data mining.