 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Utterance Language Models with Acoustic Error Sampling
Paper and Code
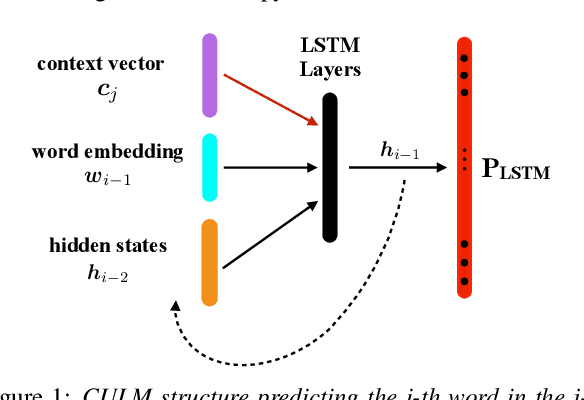

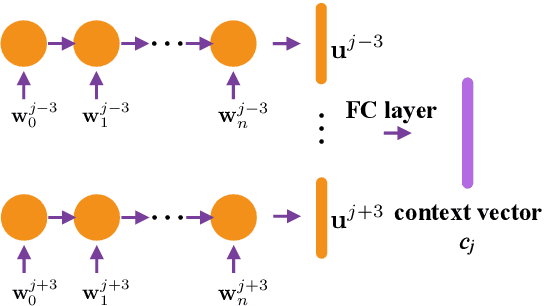

The effective exploitation of richer contextual information in language models (LMs) is a long-standing research problem for automatic speech recognition (ASR). A cross-utterance LM (CULM) is proposed in this paper, which augments the input to a standard long short-term memory (LSTM) LM with a context vector derived from past and future utterances using an extraction network. The extraction network uses another LSTM to encode surrounding utterances into vectors which are integrated into a context vector using either a projection of LSTM final hidden states, or a multi-head self-attentive layer. In addition, an acoustic error sampling technique is proposed to reduce the mismatch between training and test-time. This is achieved by considering possible ASR errors into the model training procedure, and can therefore improve the word error rate (WER). Experiments performed on both AMI and Switchboard datasets show that CULMs outperform the LSTM LM baseline WER. In particular, the CULM with a self-attentive layer-based extraction network and acoustic error sampling achieves 0.6% absolute WER reduction on AMI, 0.3% WER reduction on the Switchboard part and 0.9% WER reduction on the Callhome part of Eval2000 test set over the respective baselines.