 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Pixel Optical Flow Similarity for Self-Supervised Learning
Paper and Code
Jul 15, 2018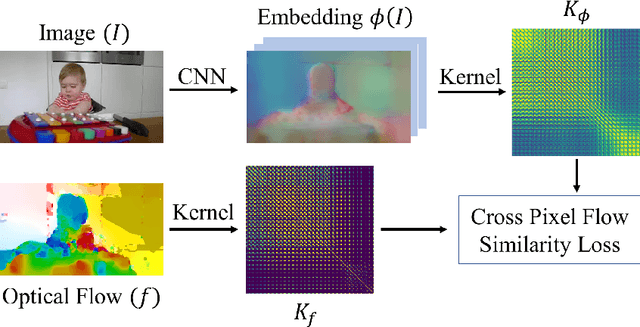
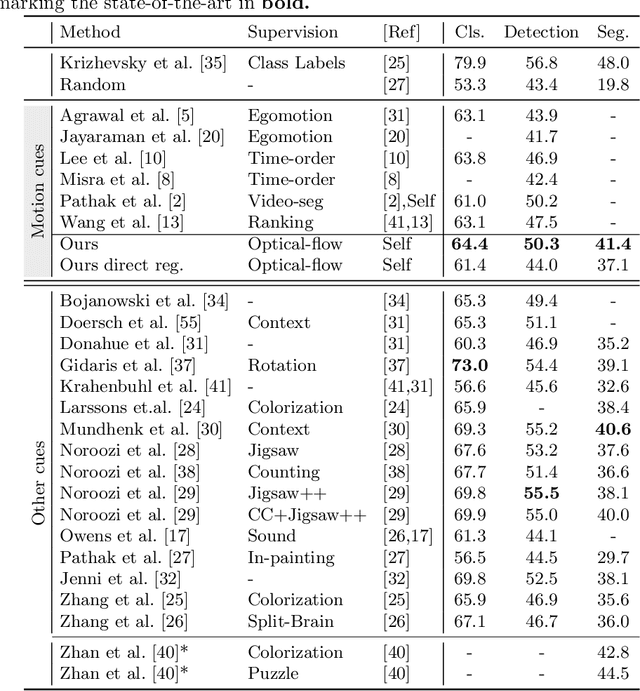
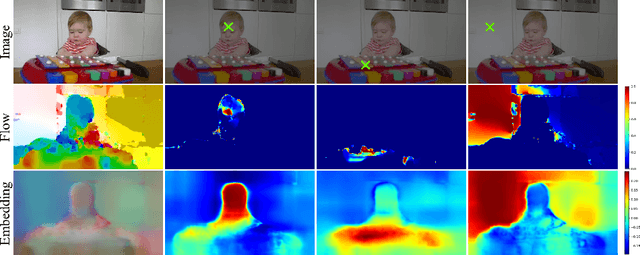
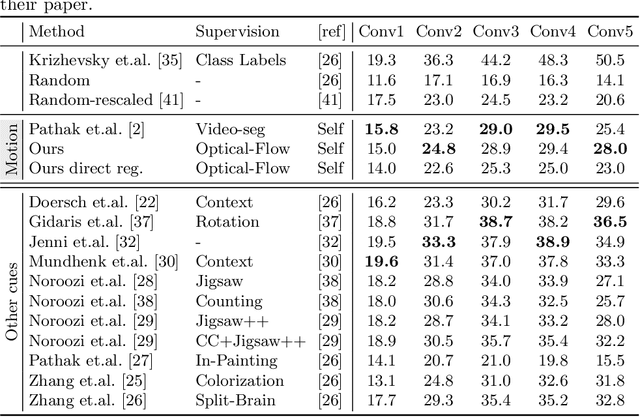
We propose a novel method for learning convolutional neural image representations without manual supervision. We use motion cues in the form of optical flow, to supervise representations of static images. The obvious approach of training a network to predict flow from a single image can be needlessly difficult due to intrinsic ambiguities in this prediction task. We instead propose a much simpler learning goal: embed pixels such that the similarity between their embeddings matches that between their optical flow vectors. At test time, the learned deep network can be used without access to video or flow information and transferred to tasks such as image classification, detection, and segmentation. Our method, which significantly simplifies previous attempts at using motion for self-supervision, achieves state-of-the-art results in self-supervision using motion cues, competitive results for self-supervision in general, and is overall state of the art in self-supervised pretraining for semantic image segmentation, as demonstrated on standard benchmarks.