 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Knowledge Transfer via Inter-Modal Translation and Alignment for Affect Recognition
Paper and Code
Aug 02, 2021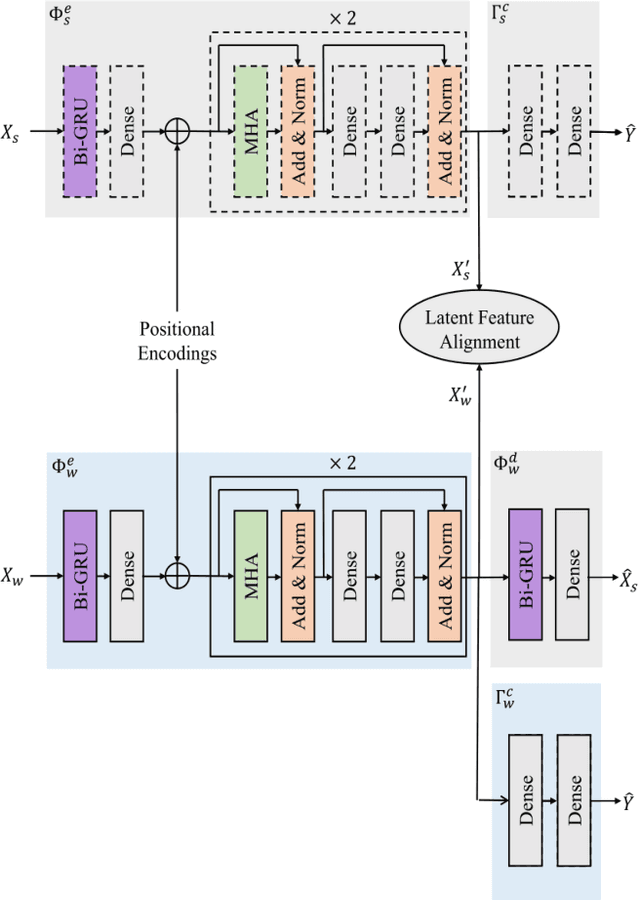
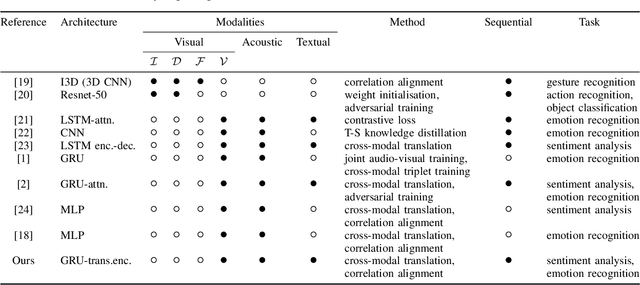
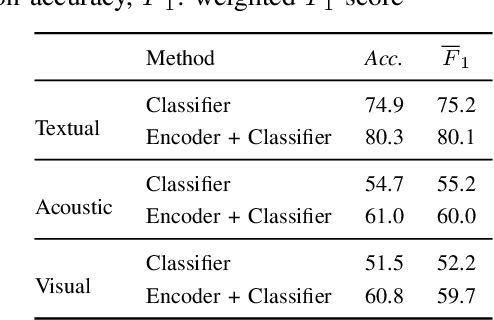
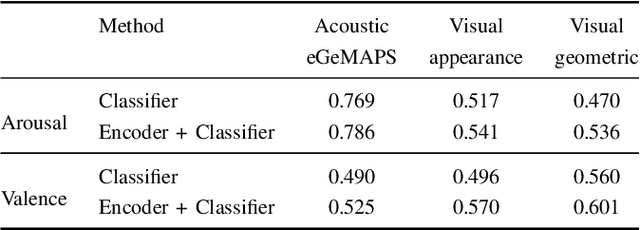
Multi-modal affect recognition models leverage complementary information in different modalities to outperform their uni-modal counterparts. However, due to the unavailability of modality-specific sensors or data, multi-modal models may not be always employable. For this reason, we aim to improve the performance of uni-modal affect recognition models by transferring knowledge from a better-performing (or stronger) modality to a weaker modality during training. Our proposed multi-modal training framework for cross-modal knowledge transfer relies on two main steps. First, an encoder-classifier model creates task-specific representations for the stronger modality. Then, cross-modal translation generates multi-modal intermediate representations, which are also aligned in the latent space with the stronger modality representations. To exploit the contextual information in temporal sequential affect data, we use Bi-GRU and transformer encoder. We validate our approach on two multi-modal affect datasets, namely CMU-MOSI for binary sentiment classification and RECOLA for dimensional emotion regression. The results show that the proposed approach consistently improves the uni-modal test-time performance of the weaker modalities.