 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Inductive Transfer to Detect Offensive Language
Paper and Code
Jul 07, 2020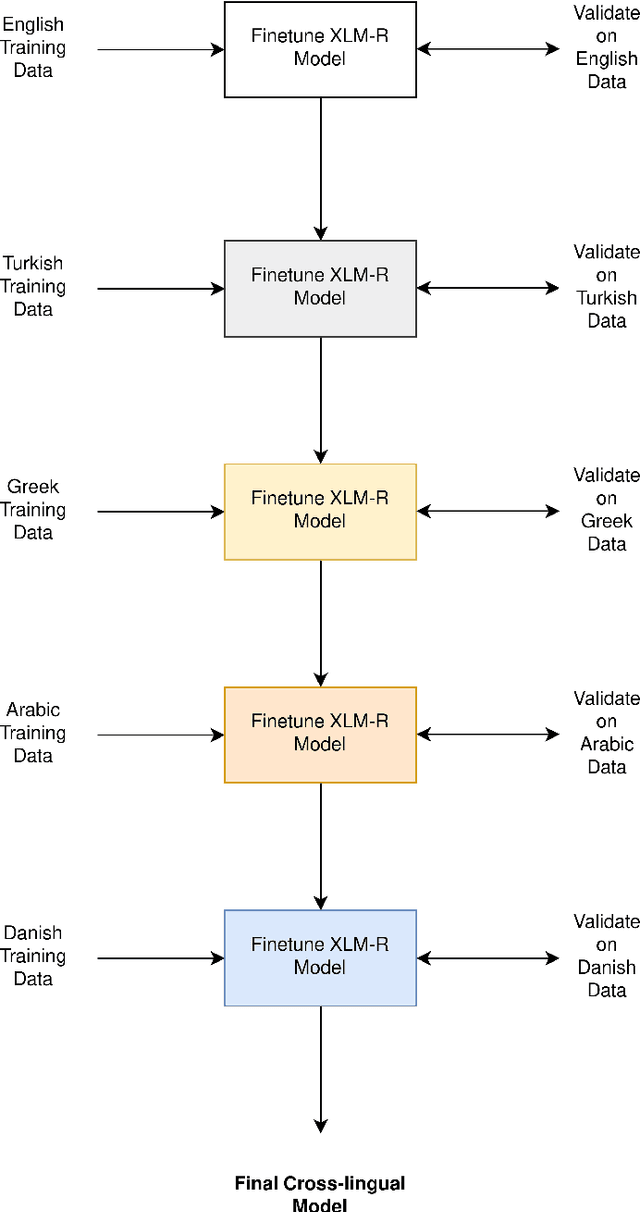
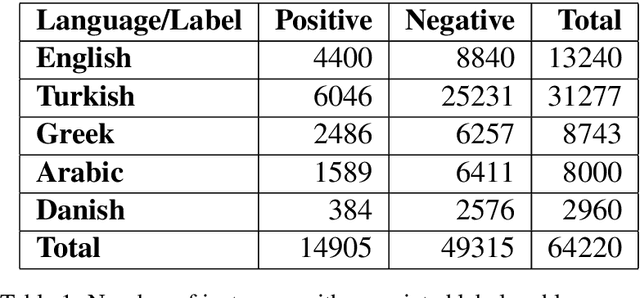
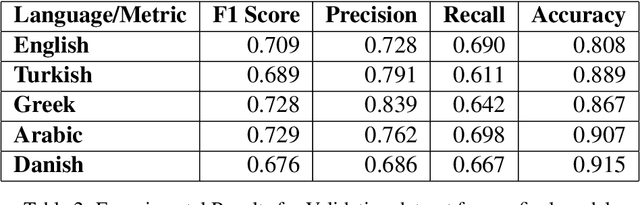
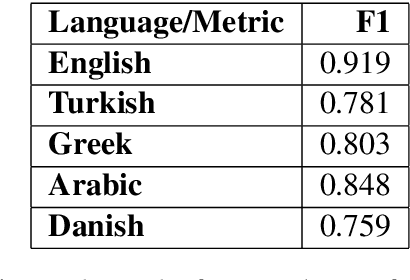
With the growing use of social media and its availability, many instances of the use of offensive language have been observed across multiple languages and domains. This phenomenon has given rise to the growing need to detect the offensive language used in social media cross-lingually. In OffensEval 2020, the organizers have released the \textit{multilingual Offensive Language Identification Dataset} (mOLID), which contains tweets in five different languages, to detect offensive language. In this work, we introduce a cross-lingual inductive approach to identify the offensive language in tweets using the contextual word embedding \textit{XLM-RoBERTa} (XLM-R). We show that our model performs competitively on all five languages, obtaining the fourth position in the English task with an F1-score of $0.919$ and eighth position in the Turkish task with an F1-score of $0.781$. Further experimentation proves that our model works competitively in a zero-shot learning environment, and is extensible to other languages.