 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual and Multilingual Speech Emotion Recognition on English and French
Paper and Code
Mar 01, 2018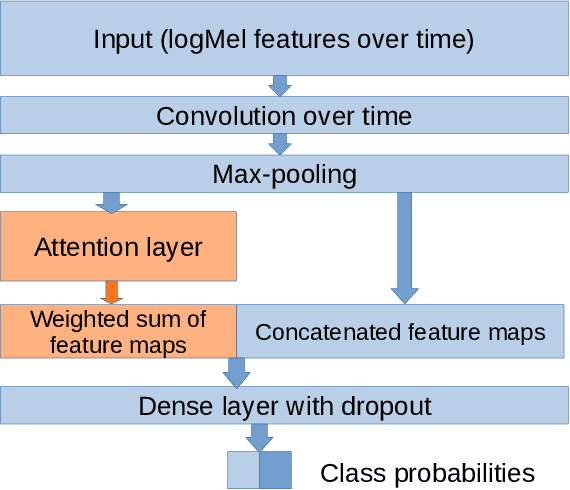
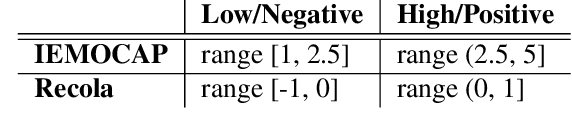
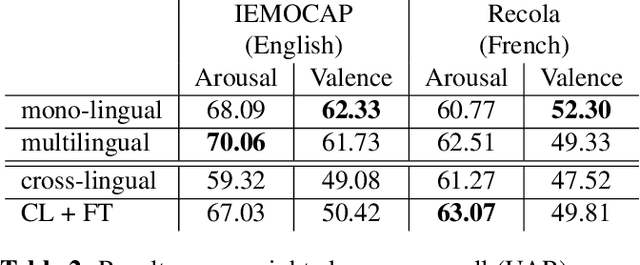
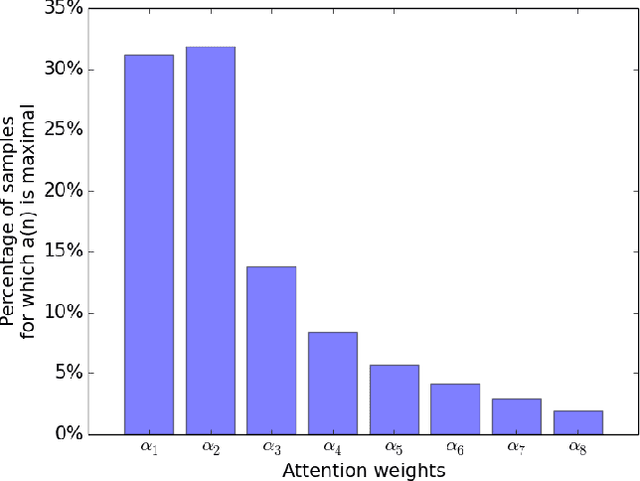
Research on multilingual speech emotion recognition faces the problem that most available speech corpora differ from each other in important ways, such as annotation methods or interaction scenarios. These inconsistencies complicate building a multilingual system. We present results for cross-lingual and multilingual emotion recognition on English and French speech data with similar characteristics in terms of interaction (human-human conversations). Further, we explore the possibility of fine-tuning a pre-trained cross-lingual model with only a small number of samples from the target language, which is of great interest for low-resource languages. To gain more insights in what is learned by the deployed convolutional neural network, we perform an analysis on the attention mechanism inside the network.