 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit risk prediction in an imbalanced social lending environment
Paper and Code
Apr 28, 2018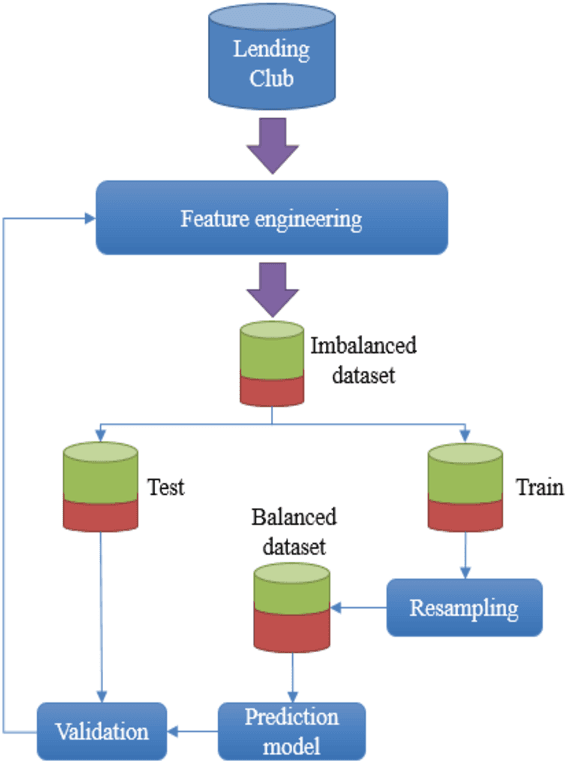
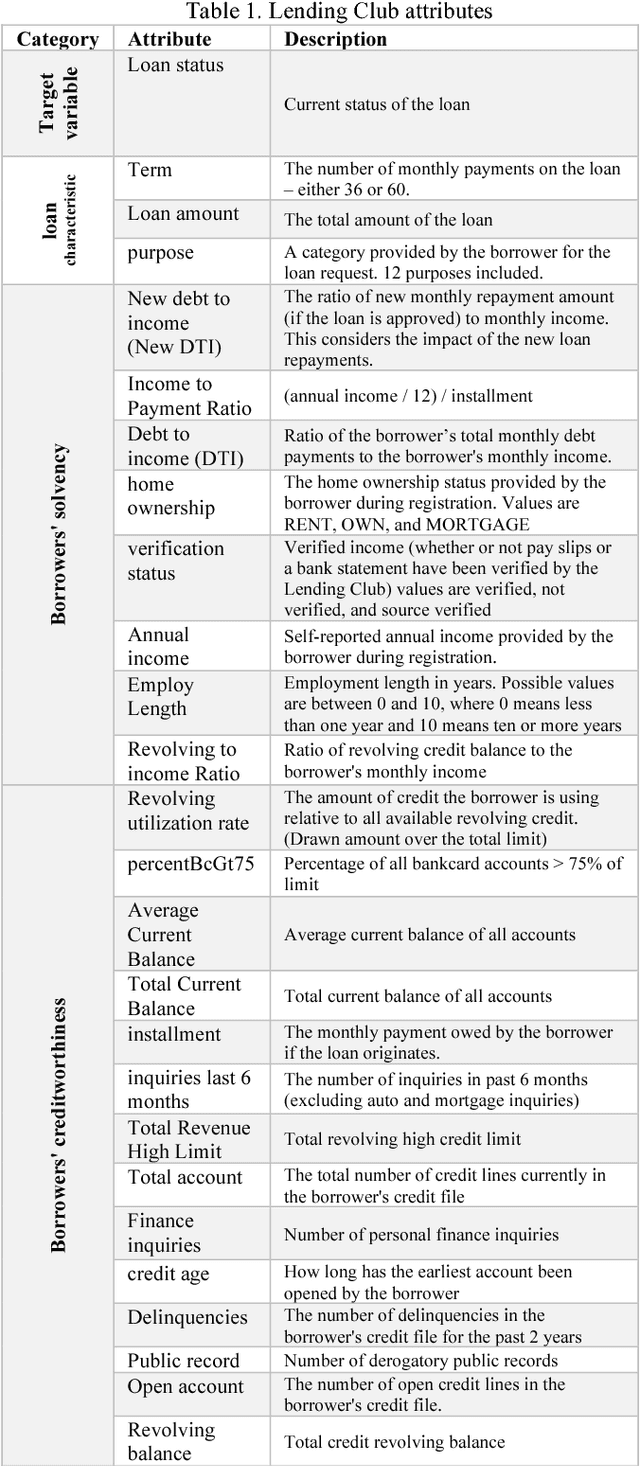
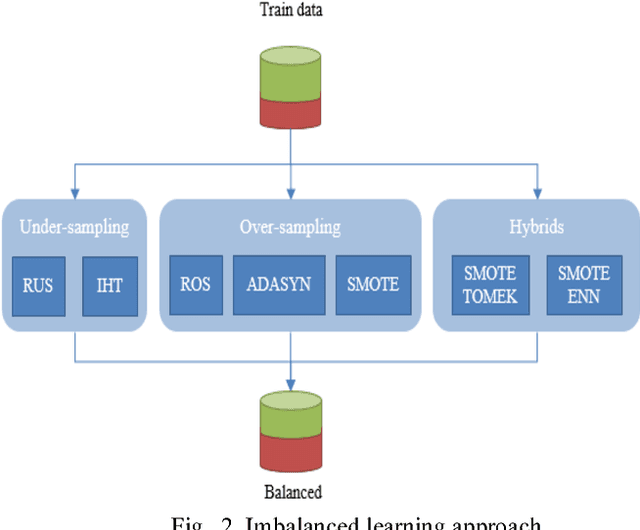
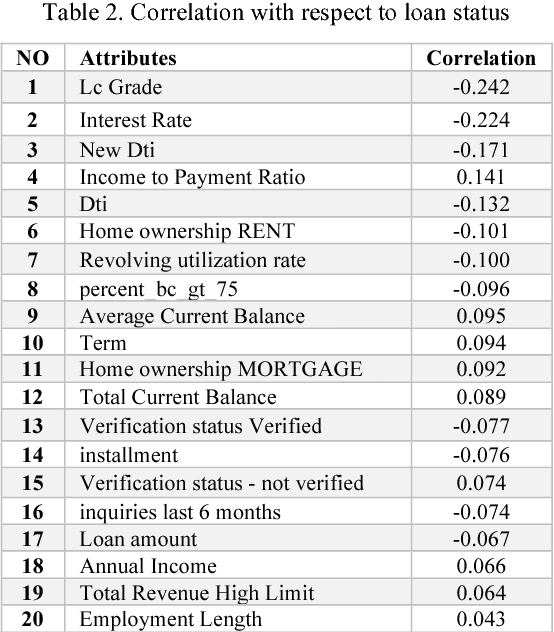
Credit risk prediction is an effective way of evaluating whether a potential borrower will repay a loan, particularly in peer-to-peer lending where class imbalance problems are prevalent. However, few credit risk prediction models for social lending consider imbalanced data and, further, the best resampling technique to use with imbalanced data is still controversial. In an attempt to address these problems, this paper presents an empirical comparison of various combinations of classifiers and resampling techniques within a novel risk assessment methodology that incorporates imbalanced data. The credit predictions from each combination are evaluated with a G-mean measure to avoid bias towards the majority class, which has not been considered in similar studies. The results reveal that combining random forest and random under-sampling may be an effective strategy for calculating the credit risk associated with loan applicants in social lending markets.