 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a Universal Dependencies Treebank of Spoken Frisian-Dutch Code-switched Data
Paper and Code
Feb 22, 2021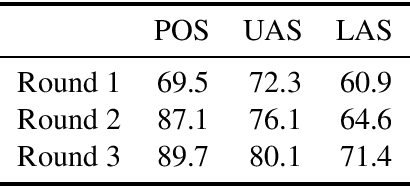
This paper explores the difficulties of annotating transcribed spoken Dutch-Frisian code-switch utterances into Universal Dependencies. We make use of data from the FAME! corpus, which consists of transcriptions and audio data. Besides the usual annotation difficulties, this dataset is extra challenging because of Frisian being low-resource, the informal nature of the data, code-switching and non-standard sentence segmentation. As a starting point, two annotators annotated 150 random utterances in three stages of 50 utterances. After each stage, disagreements where discussed and resolved. An increase of 7.8 UAS and 10.5 LAS points was achieved between the first and third round. This paper will focus on the issues that arise when annotating a transcribed speech corpus. To resolve these issues several solutions are proposed.