Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting Momentum with Second-order Information
Paper and Code
Mar 04, 2021

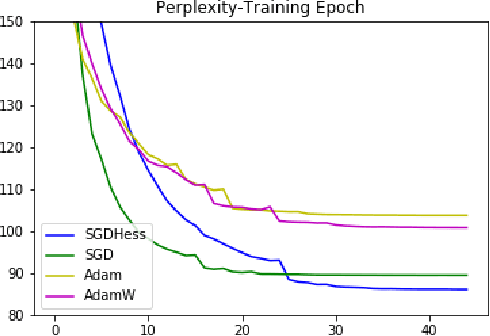
We develop a new algorithm for non-convex stochastic optimization that finds an $\epsilon$-critical point in the optimal $O(\epsilon^{-3})$ stochastic gradient and hessian-vector product computations. Our algorithm uses Hessian-vector products to "correct" a bias term in the momentum of SGD with momentum. This leads to better gradient estimates in a manner analogous to variance reduction methods. In contrast to prior work, we do not require excessively large batch sizes (or indeed any restrictions at all on the batch size), and both our algorithm and its analysis are much simpler. We validate our results on a variety of large-scale deep learning benchmarks and architectures, where we see improvements over SGD and Adam.
View paper on