Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus Statistics in Text Classification of Online Data
Paper and Code
Mar 16, 2018
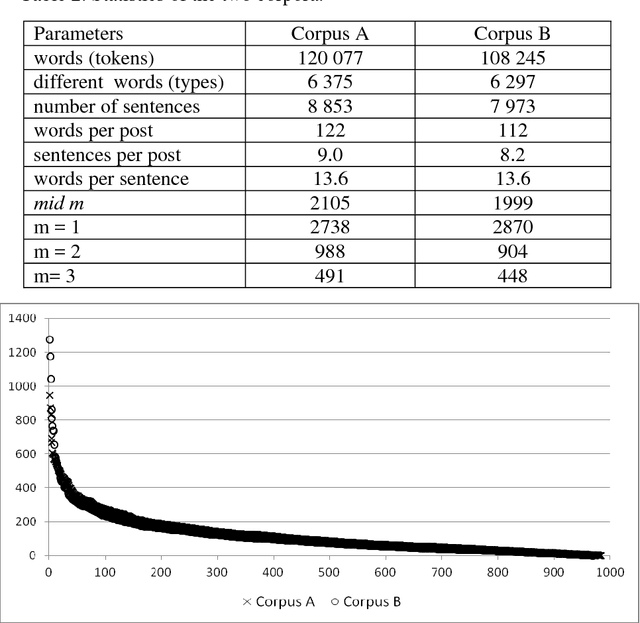
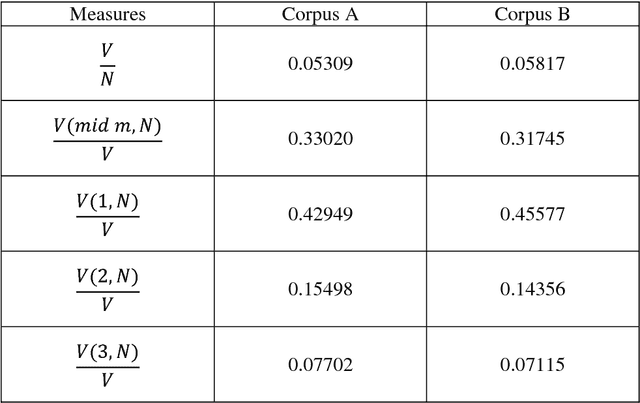

Transformation of Machine Learning (ML) from a boutique science to a generally accepted technology has increased importance of reproduction and transportability of ML studies. In the current work, we investigate how corpus characteristics of textual data sets correspond to text classification results. We work with two data sets gathered from sub-forums of an online health-related forum. Our empirical results are obtained for a multi-class sentiment analysis application.
* 12 pages, 6 tables, 1 figure
View paper on