 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Learning with Visual Attributes
Paper and Code
May 16, 2017
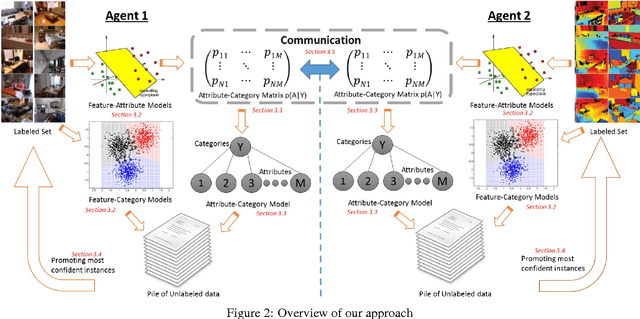
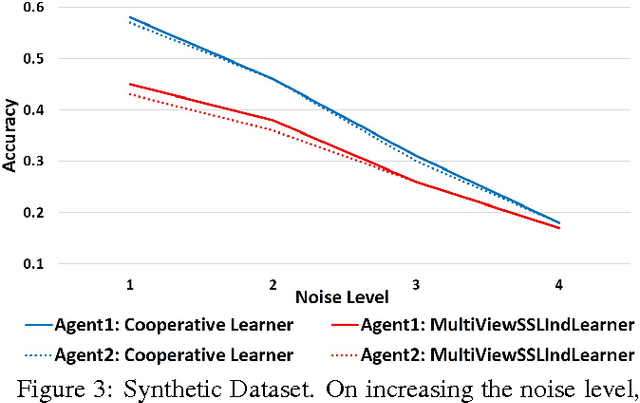

Learning paradigms involving varying levels of supervision have received a lot of interest within the computer vision and machine learning communities. The supervisory information is typically considered to come from a human supervisor -- a "teacher" figure. In this paper, we consider an alternate source of supervision -- a "peer" -- i.e. a different machine. We introduce cooperative learning, where two agents trying to learn the same visual concepts, but in potentially different environments using different sources of data (sensors), communicate their current knowledge of these concepts to each other. Given the distinct sources of data in both agents, the mode of communication between the two agents is not obvious. We propose the use of visual attributes -- semantic mid-level visual properties such as furry, wooden, etc.-- as the mode of communication between the agents. Our experiments in three domains -- objects, scenes, and animals -- demonstrate that our proposed cooperative learning approach improves the performance of both agents as compared to their performance if they were to learn in isolation. Our approach is particularly applicable in scenarios where privacy, security and/or bandwidth constraints restrict the amount and type of information the two agents can exchange.