Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Attention Networks for Multimodal Emotion Recognition from Speech and Text Data
Paper and Code
May 17, 2018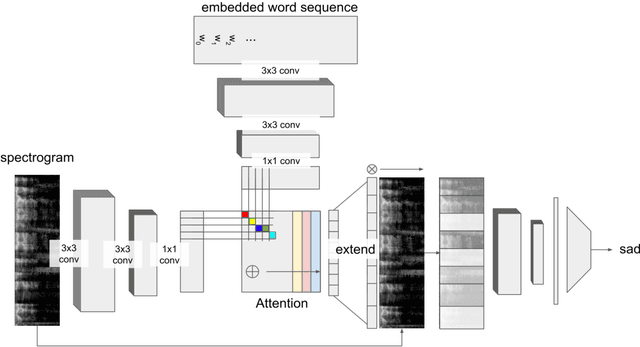
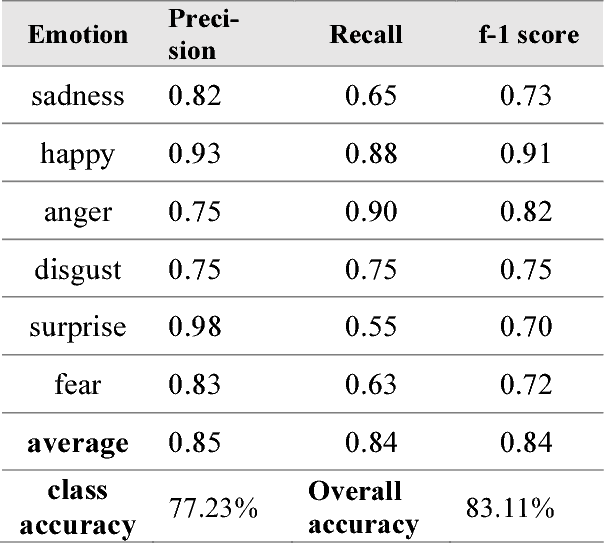


Emotion recognition has become a popular topic of interest, especially in the field of human computer interaction. Previous works involve unimodal analysis of emotion, while recent efforts focus on multi-modal emotion recognition from vision and speech. In this paper, we propose a new method of learning about the hidden representations between just speech and text data using convolutional attention networks. Compared to the shallow model which employs simple concatenation of feature vectors, the proposed attention model performs much better in classifying emotion from speech and text data contained in the CMU-MOSEI dataset.
View paper on