 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolution-Free Medical Image Segmentation using Transformers
Paper and Code
Feb 26, 2021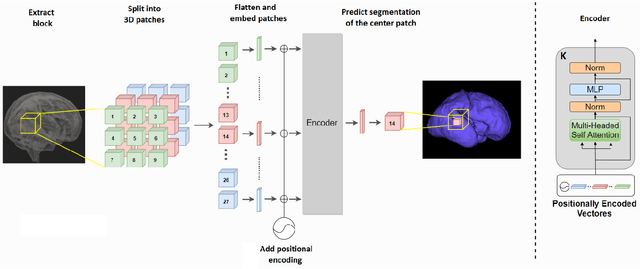
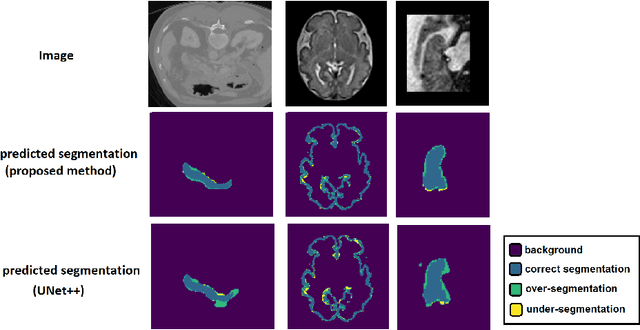
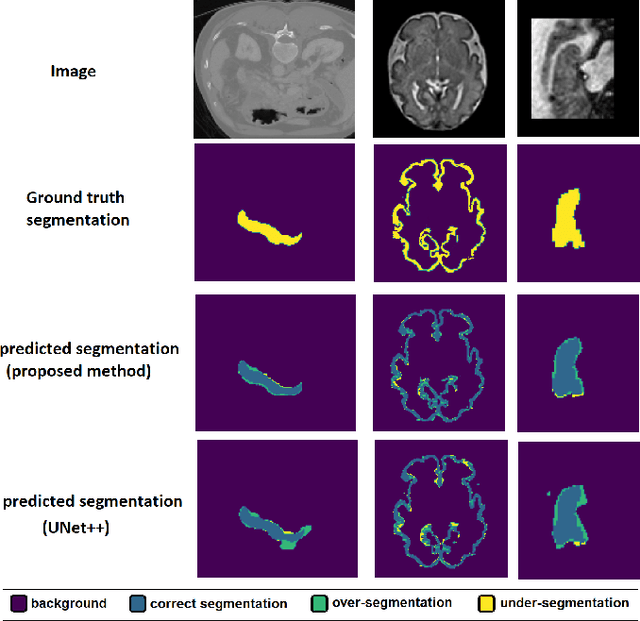
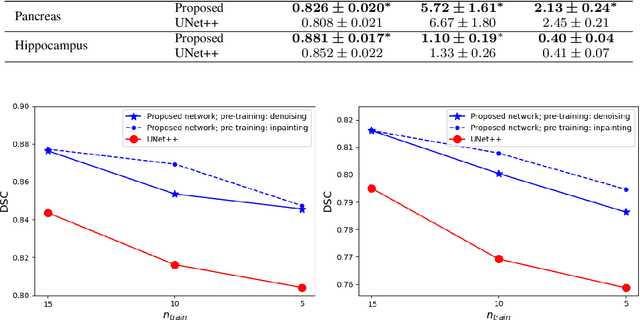
Like other applications in computer vision, medical image segmentation has been most successfully addressed using deep learning models that rely on the convolution operation as their main building block. Convolutions enjoy important properties such as sparse interactions, weight sharing, and translation equivariance. These properties give convolutional neural networks (CNNs) a strong and useful inductive bias for vision tasks. In this work we show that a different method, based entirely on self-attention between neighboring image patches and without any convolution operations, can achieve competitive or better results. Given a 3D image block, our network divides it into $n^3$ 3D patches, where $n=3 \text{ or } 5$ and computes a 1D embedding for each patch. The network predicts the segmentation map for the center patch of the block based on the self-attention between these patch embeddings. We show that the proposed model can achieve segmentation accuracies that are better than the state of the art CNNs on three datasets. We also propose methods for pre-training this model on large corpora of unlabeled images. Our experiments show that with pre-training the advantage of our proposed network over CNNs can be significant when labeled training data is small.