 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Hierarchical Clustering for Graph-Structured Data
Paper and Code
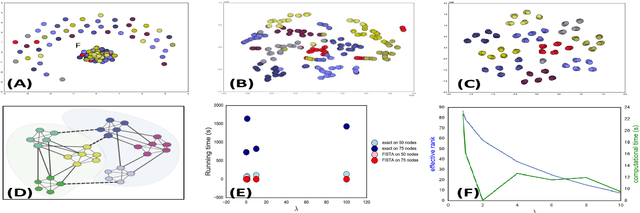
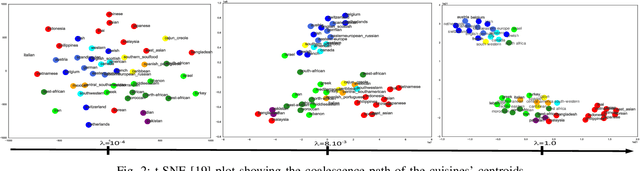
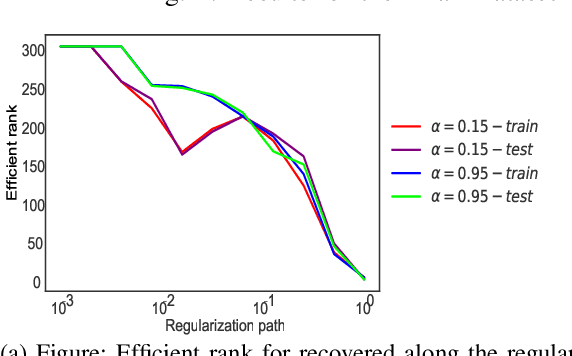
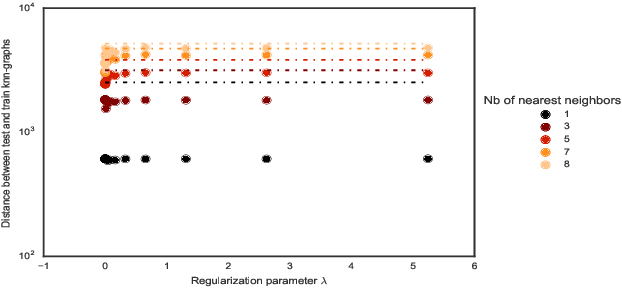
Convex clustering is a recent stable alternative to hierarchical clustering. It formulates the recovery of progressively coalescing clusters as a regularized convex problem. While convex clustering was originally designed for handling Euclidean distances between data points, in a growing number of applications, the data is directly characterized by a similarity matrix or weighted graph. In this paper, we extend the robust hierarchical clustering approach to these broader classes of similarities. Having defined an appropriate convex objective, the crux of this adaptation lies in our ability to provide: (a) an efficient recovery of the regularization path and (b) an empirical demonstration of the use of our method. We address the first challenge through a proximal dual algorithm, for which we characterize both the theoretical efficiency as well as the empirical performance on a set of experiments. Finally, we highlight the potential of our method by showing its application to several real-life datasets, thus providing a natural extension to the current scope of applications of convex clustering.