Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence Guarantees for Deep Epsilon Greedy Policy Learning
Paper and Code
Dec 02, 2021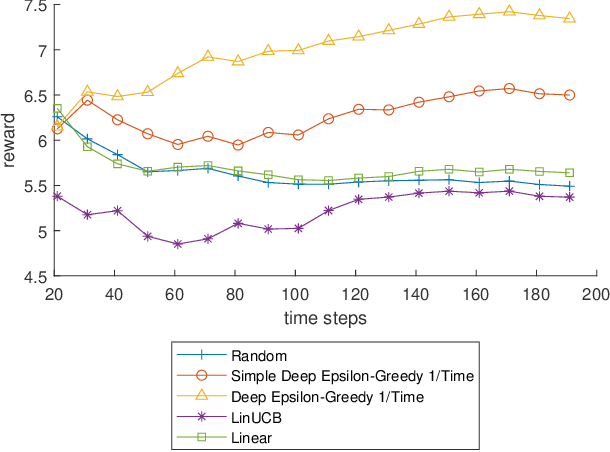
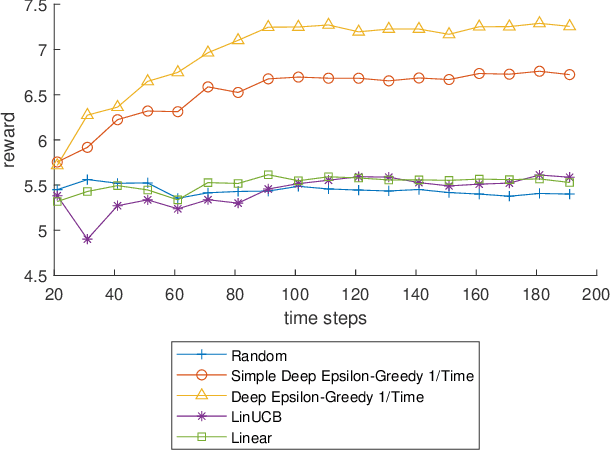
Policy learning is a quickly growing area. As robotics and computers control day-to-day life, their error rate needs to be minimized and controlled. There are many policy learning methods and provable error rates that accompany them. We show an error or regret bound and convergence of the Deep Epsilon Greedy method which chooses actions with a neural network's prediction. In experiments with the real-world dataset MNIST, we construct a nonlinear reinforcement learning problem. We witness how with either high or low noise, some methods do and some do not converge which agrees with our proof of convergence.
View paper on