Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence and Implicit Regularization Properties of Gradient Descent for Deep Residual Networks
Paper and Code
Apr 14, 2022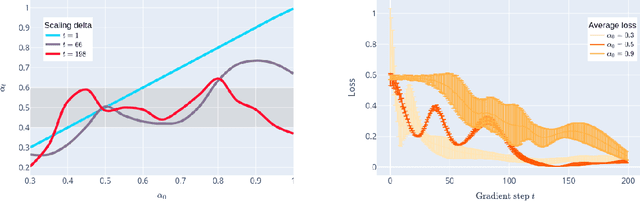

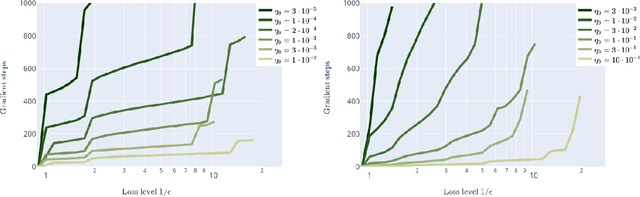
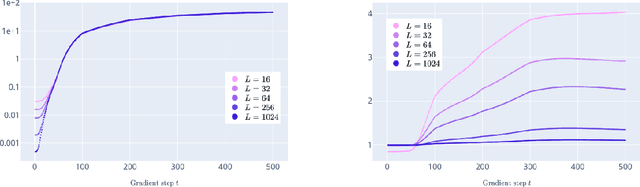
We prove linear convergence of gradient descent to a global minimum for the training of deep residual networks with constant layer width and smooth activation function. We further show that the trained weights, as a function of the layer index, admits a scaling limit which is H\"older continuous as the depth of the network tends to infinity. The proofs are based on non-asymptotic estimates of the loss function and of norms of the network weights along the gradient descent path. We illustrate the relevance of our theoretical results to practical settings using detailed numerical experiments on supervised learning problems.
View paper on