 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence and Accuracy Trade-Offs in Federated Learning and Meta-Learning
Paper and Code
Mar 08, 2021
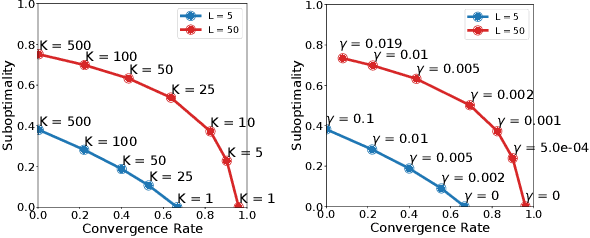

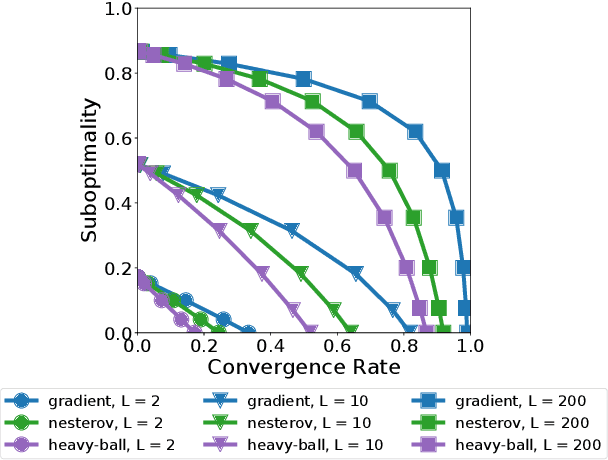
We study a family of algorithms, which we refer to as local update methods, generalizing many federated and meta-learning algorithms. We prove that for quadratic models, local update methods are equivalent to first-order optimization on a surrogate loss we exactly characterize. Moreover, fundamental algorithmic choices (such as learning rates) explicitly govern a trade-off between the condition number of the surrogate loss and its alignment with the true loss. We derive novel convergence rates showcasing these trade-offs and highlight their importance in communication-limited settings. Using these insights, we are able to compare local update methods based on their convergence/accuracy trade-off, not just their convergence to critical points of the empirical loss. Our results shed new light on a broad range of phenomena, including the efficacy of server momentum in federated learning and the impact of proximal client updates.