 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Self-supervised Learning for Graph Classification
Paper and Code
Sep 13, 2020
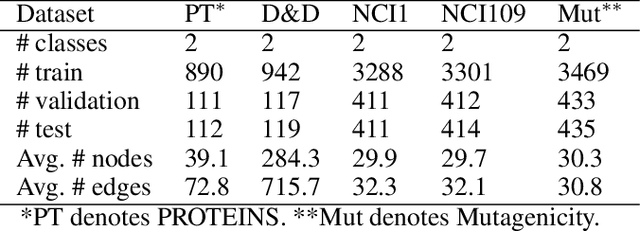
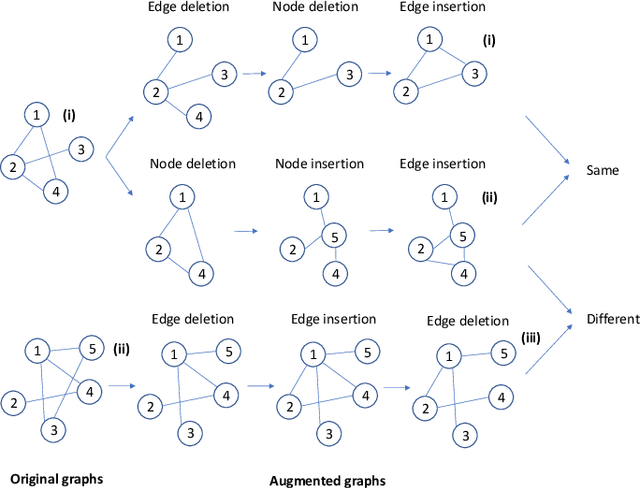

Graph classification is a widely studied problem and has broad applications. In many real-world problems, the number of labeled graphs available for training classification models is limited, which renders these models prone to overfitting. To address this problem, we propose two approaches based on contrastive self-supervised learning (CSSL) to alleviate overfitting. In the first approach, we use CSSL to pretrain graph encoders on widely-available unlabeled graphs without relying on human-provided labels, then finetune the pretrained encoders on labeled graphs. In the second approach, we develop a regularizer based on CSSL, and solve the supervised classification task and the unsupervised CSSL task simultaneously. To perform CSSL on graphs, given a collection of original graphs, we perform data augmentation to create augmented graphs out of the original graphs. An augmented graph is created by consecutively applying a sequence of graph alteration operations. A contrastive loss is defined to learn graph encoders by judging whether two augmented graphs are from the same original graph. Experiments on various graph classification datasets demonstrate the effectiveness of our proposed methods.