 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Multiple Correspondence Analysis (cMCA): Applying the Contrastive Learning Method to Identify Political Subgroups
Paper and Code
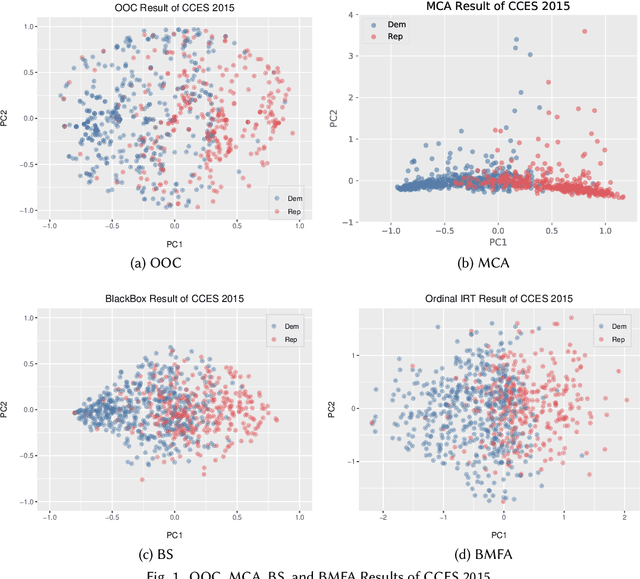
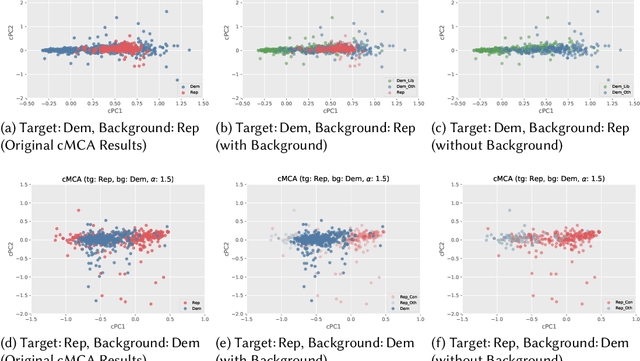
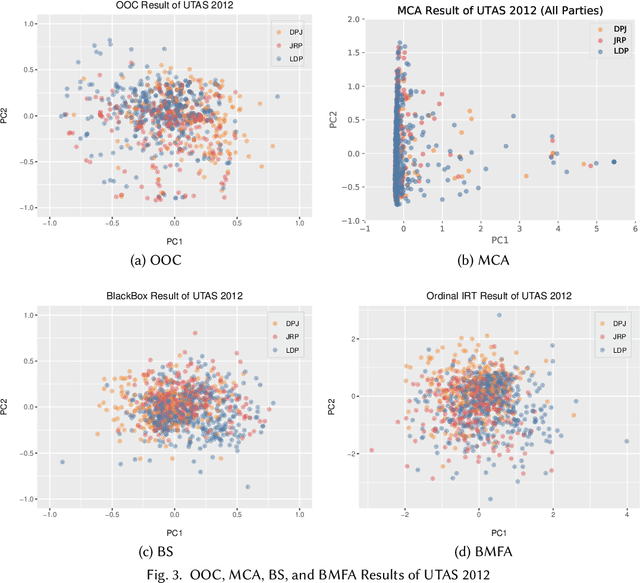
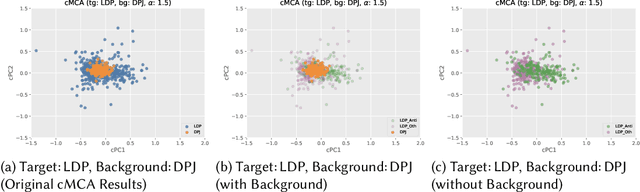
Ideal point estimation and dimensionality reduction have long been utilized to simplify and cluster complex, high-dimensional political data (e.g., roll-call votes and surveys) for use in analysis and visualization. These methods often work by finding the directions or principal components (PCs) on which either the data varies the most or respondents make the fewest decision errors. However, these PCs, which usually reflect the left-right political spectrum, are sometimes uninformative in explaining significant differences in the distribution of the data (e.g., how to categorize a set of highly-moderate voters). To tackle this issue, we adopt an emerging analysis approach, called contrastive learning. Contrastive learning-e.g., contrastive principal component analysis (cPCA)-works by first splitting the data by predefined groups, and then deriving PCs on which the target group varies the most but the background group varies the least. As a result, cPCA can often find `hidden' patterns, such as subgroups within the target group, which PCA cannot reveal when some variables are the dominant source of variations across the groups. We contribute to the field of contrastive learning by extending it to multiple correspondence analysis (MCA) to enable an analysis of data often encountered by social scientists---namely binary, ordinal, and nominal variables. We demonstrate the utility of contrastive MCA (cMCA) by analyzing three different surveys: The 2015 Cooperative Congressional Election Study, 2012 UTokyo-Asahi Elite Survey, and 2018 European Social Survey. Our results suggest that, first, for the cases when ordinary MCA depicts differences between groups, cMCA can further identify characteristics that divide the target group; second, for the cases when MCA does not show clear differences, cMCA can successfully identify meaningful directions and subgroups, which traditional methods overlook.