 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContraction Principle based Robust Iterative Algorithms for Machine Learning
Paper and Code
Oct 05, 2013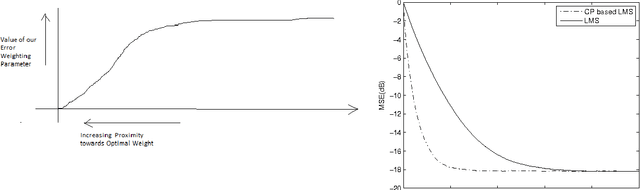
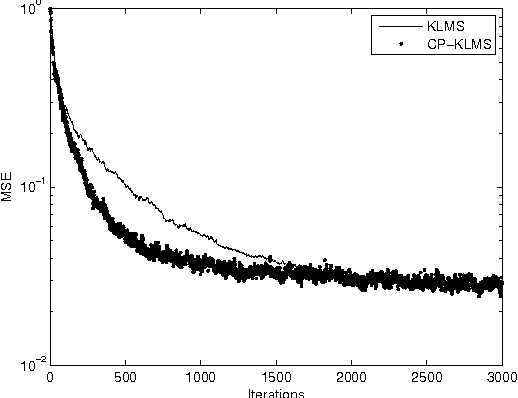


Iterative algorithms are ubiquitous in the field of data mining. Widely known examples of such algorithms are the least mean square algorithm, backpropagation algorithm of neural networks. Our contribution in this paper is an improvement upon this iterative algorithms in terms of their respective performance metrics and robustness. This improvement is achieved by a new scaling factor which is multiplied to the error term. Our analysis shows that in essence, we are minimizing the corresponding LASSO cost function, which is the reason of its increased robustness. We also give closed form expressions for the number of iterations for convergence and the MSE floor of the original cost function for a minimum targeted value of the L1 norm. As a concluding theme based on the stochastic subgradient algorithm, we give a comparison between the well known Dantzig selector and our algorithm based on contraction principle. By these simulations we attempt to show the optimality of our approach for any widely used parent iterative optimization problem.