 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Emotion Recognition with Spatiotemporal Convolutional Neural Networks
Paper and Code
Nov 18, 2020
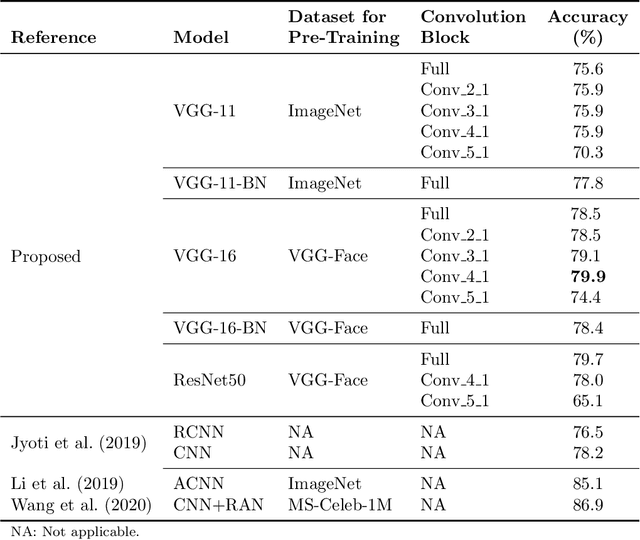
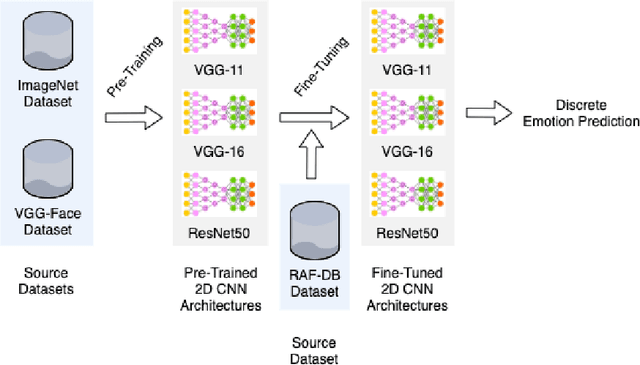
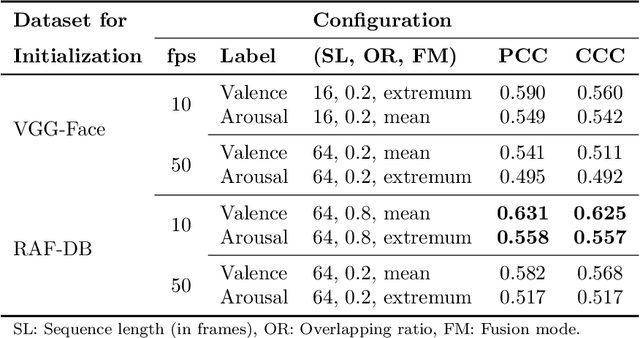
The attention in affect computing and emotion recognition has increased in the last decade. Facial expressions are one of the most powerful ways for depicting specific patterns in human behavior and describing human emotional state. Nevertheless, even for humans, identifying facial expressions is difficult, and automatic video-based systems for facial expression recognition (FER) have often suffered from variations in expressions among individuals, and from a lack of diverse and cross-culture training datasets. However, with video sequences captured in-the-wild and more complex emotion representation such as dimensional models, deep FER systems have the ability to learn more discriminative feature representations. In this paper, we present a survey of the state-of-the-art approaches based on convolutional neural networks (CNNs) for long video sequences recorded with in-the-wild settings, by considering the continuous emotion space of valence and arousal. Since few studies have used 3D-CNN for FER systems and dimensional representation of emotions, we propose an inflated 3D-CNN architecture, allowing for weight inflation of pre-trained 2D-CNN model, in order to operate the essential transfer learning for our video-based application. As a baseline, we also considered a 2D-CNN architecture cascaded network with a long short term memory network, therefore we could finally conclude with a model comparison over two approaches for spatiotemporal representation of facial features and performing the regression of valence/arousal values for emotion prediction. The experimental results on RAF-DB and SEWA-DB datasets have shown that these fine-tuned architectures allow to effectively encode the spatiotemporal information from raw pixel images, and achieved far better results than the current state-of-the-art.