 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Bandits with Knapsacks for a Conversion Model
Paper and Code
Jun 01, 2022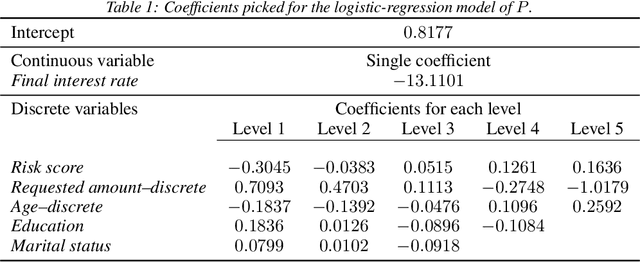
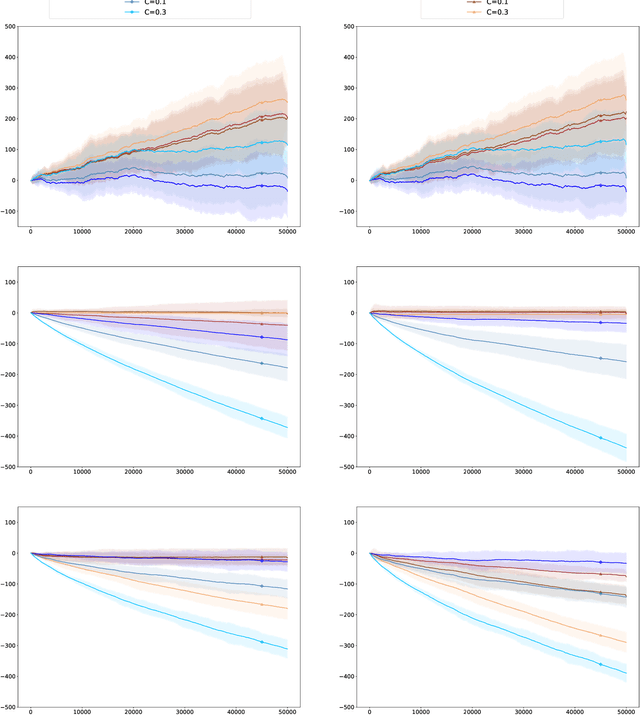
We consider contextual bandits with knapsacks, with an underlying structure between rewards generated and cost vectors suffered. We do so motivated by sales with commercial discounts. At each round, given the stochastic i.i.d.\ context $\mathbf{x}_t$ and the arm picked $a_t$ (corresponding, e.g., to a discount level), a customer conversion may be obtained, in which case a reward $r(a,\mathbf{x}_t)$ is gained and vector costs $c(a_t,\mathbf{x}_t)$ are suffered (corresponding, e.g., to losses of earnings). Otherwise, in the absence of a conversion, the reward and costs are null. The reward and costs achieved are thus coupled through the binary variable measuring conversion or the absence thereof. This underlying structure between rewards and costs is different from the linear structures considered by Agrawal and Devanur [2016] but we show that the techniques introduced in this article may also be applied to the latter case. Namely, the adaptive policies exhibited solve at each round a linear program based on upper-confidence estimates of the probabilities of conversion given $a$ and $\mathbf{x}$. This kind of policy is most natural and achieves a regret bound of the typical order (OPT/$B$) $\sqrt{T}$, where $B$ is the total budget allowed, OPT is the optimal expected reward achievable by a static policy, and $T$ is the number of rounds.