 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Bandits for adapting to changing User preferences over time
Paper and Code
Sep 23, 2020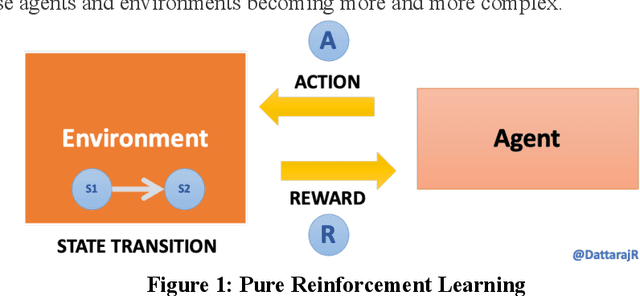
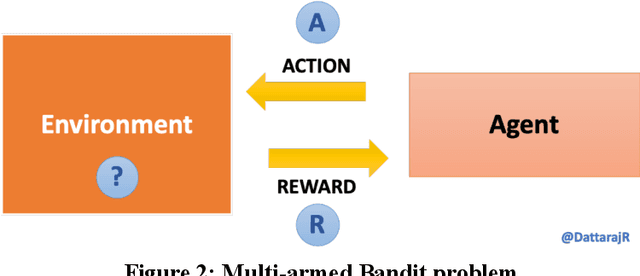

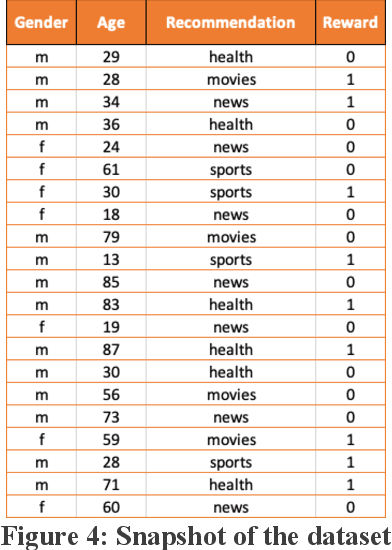
Contextual bandits provide an effective way to model the dynamic data problem in ML by leveraging online (incremental) learning to continuously adjust the predictions based on changing environment. We explore details on contextual bandits, an extension to the traditional reinforcement learning (RL) problem and build a novel algorithm to solve this problem using an array of action-based learners. We apply this approach to model an article recommendation system using an array of stochastic gradient descent (SGD) learners to make predictions on rewards based on actions taken. We then extend the approach to a publicly available MovieLens dataset and explore the findings. First, we make available a simplified simulated dataset showing varying user preferences over time and how this can be evaluated with static and dynamic learning algorithms. This dataset made available as part of this research is intentionally simulated with limited number of features and can be used to evaluate different problem-solving strategies. We will build a classifier using static dataset and evaluate its performance on this dataset. We show limitations of static learner due to fixed context at a point of time and how changing that context brings down the accuracy. Next we develop a novel algorithm for solving the contextual bandit problem. Similar to the linear bandits, this algorithm maps the reward as a function of context vector but uses an array of learners to capture variation between actions/arms. We develop a bandit algorithm using an array of stochastic gradient descent (SGD) learners, with separate learner per arm. Finally, we will apply this contextual bandit algorithm to predicting movie ratings over time by different users from the standard Movie Lens dataset and demonstrate the results.