 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Unaware Knowledge Distillation for Image Retrieval
Paper and Code
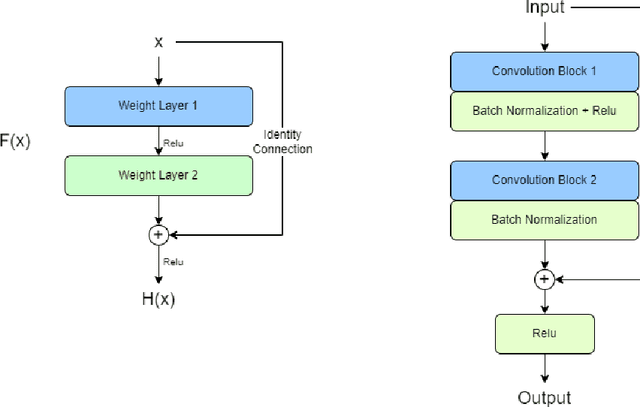
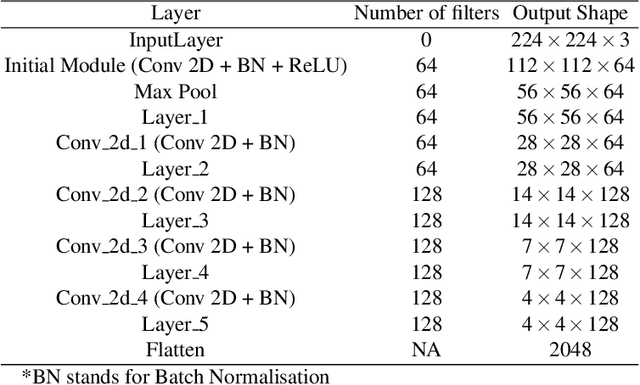

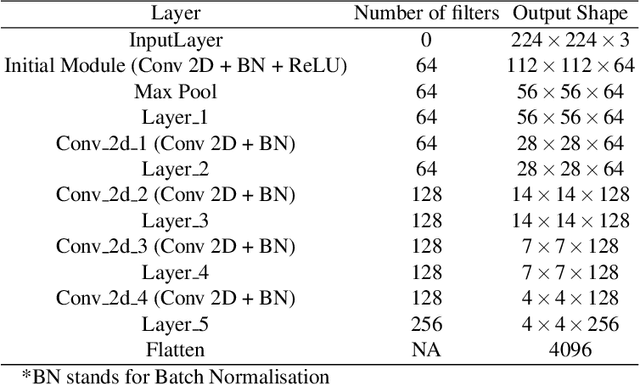
Existing data-dependent hashing methods use large backbone networks with millions of parameters and are computationally complex. Existing knowledge distillation methods use logits and other features of the deep (teacher) model and as knowledge for the compact (student) model, which requires the teacher's network to be fine-tuned on the context in parallel with the student model on the context. Training teacher on the target context requires more time and computational resources. In this paper, we propose context unaware knowledge distillation that uses the knowledge of the teacher model without fine-tuning it on the target context. We also propose a new efficient student model architecture for knowledge distillation. The proposed approach follows a two-step process. The first step involves pre-training the student model with the help of context unaware knowledge distillation from the teacher model. The second step involves fine-tuning the student model on the context of image retrieval. In order to show the efficacy of the proposed approach, we compare the retrieval results, no. of parameters and no. of operations of the student models with the teacher models under different retrieval frameworks, including deep cauchy hashing (DCH) and central similarity quantization (CSQ). The experimental results confirm that the proposed approach provides a promising trade-off between the retrieval results and efficiency. The code used in this paper is released publicly at \url{https://github.com/satoru2001/CUKDFIR}.