 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-LSTM: a robust classifier for video detection on UCF101
Paper and Code
Mar 13, 2022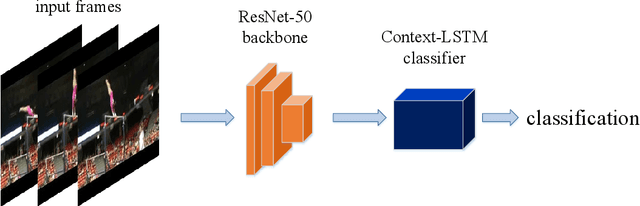

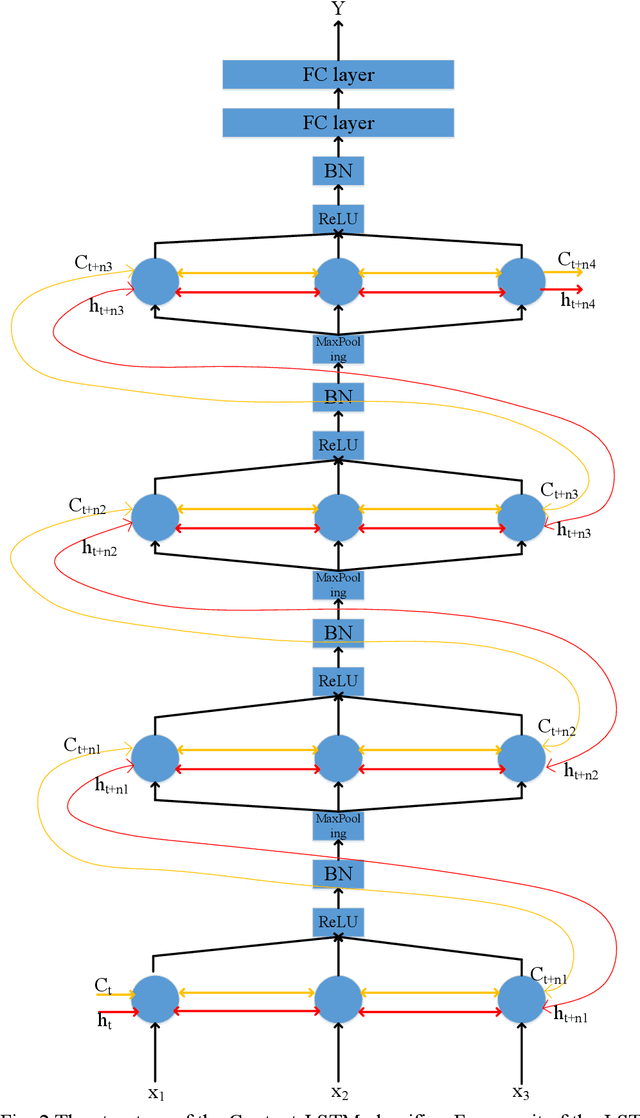

Video detection and human action recognition may be computationally expensive, and need a long time to train models. In this paper, we were intended to reduce the training time and the GPU memory usage of video detection, and achieved a competitive detection accuracy. Other research works such as Two-stream, C3D, TSN have shown excellent performance on UCF101. Here, we used a LSTM structure simply for video detection. We used a simple structure to perform a competitive top-1 accuracy on the entire validation dataset of UCF101. The LSTM structure is named Context-LSTM, since it may process the deep temporal features. The Context-LSTM may simulate the human recognition system. We cascaded the LSTM blocks in PyTorch and connected the cell state flow and hidden output flow. At the connection of the blocks, we used ReLU, Batch Normalization, and MaxPooling functions. The Context-LSTM could reduce the training time and the GPU memory usage, while keeping a state-of-the-art top-1 accuracy on UCF101 entire validation dataset, show a robust performance on video action detection.