Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraints in Developing a Complete Bengali Optical Character Recognition System
Paper and Code
Mar 22, 2020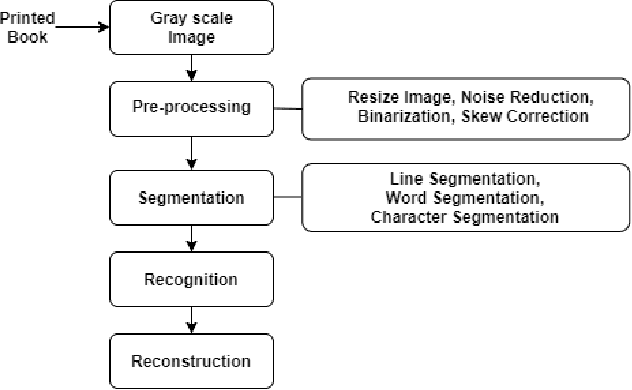


Technological advancement has led to digitizing hard copies of media effortlessly with optical character recognition (OCR) system. As OCR systems are being used constantly, converting printed or handwritten documents and books have become simple and time efficient. To be a fully functional structure, Bengali OCR system needs to overcome some constraints involved in pre-processing, segmentation and recognition phase. The aim of this research is to analyze the challenges prevalent in developing a Bengali OCR system through robust literature review and implementation.
View paper on