 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstitution or Collapse? Exploring Constitutional AI with Llama 3-8B
Paper and Code
Apr 07, 2025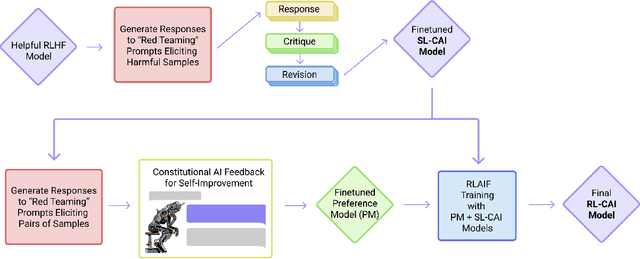

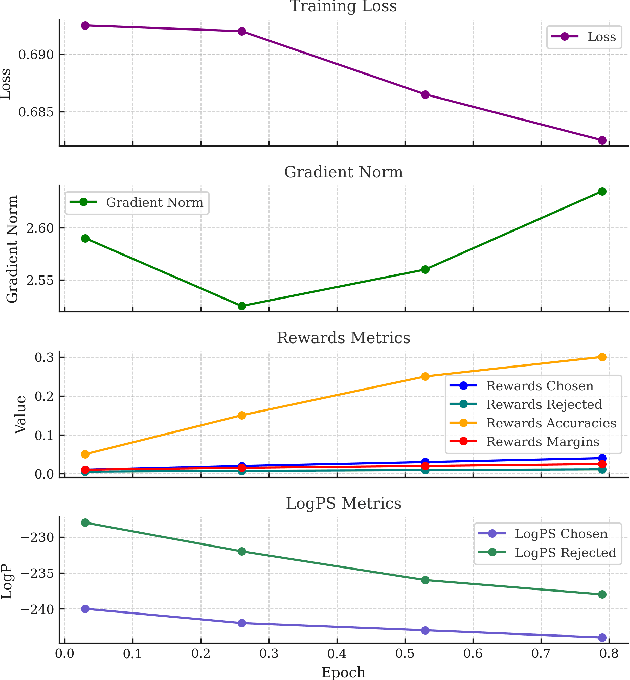

As language models continue to grow larger, the cost of acquiring high-quality training data has increased significantly. Collecting human feedback is both expensive and time-consuming, and manual labels can be noisy, leading to an imbalance between helpfulness and harmfulness. Constitutional AI, introduced by Anthropic in December 2022, uses AI to provide feedback to another AI, greatly reducing the need for human labeling. However, the original implementation was designed for a model with around 52 billion parameters, and there is limited information on how well Constitutional AI performs with smaller models, such as LLaMA 3-8B. In this paper, we replicated the Constitutional AI workflow using the smaller LLaMA 3-8B model. Our results show that Constitutional AI can effectively increase the harmlessness of the model, reducing the Attack Success Rate in MT-Bench by 40.8%. However, similar to the original study, increasing harmlessness comes at the cost of helpfulness. The helpfulness metrics, which are an average of the Turn 1 and Turn 2 scores, dropped by 9.8% compared to the baseline. Additionally, we observed clear signs of model collapse in the final DPO-CAI model, indicating that smaller models may struggle with self-improvement due to insufficient output quality, making effective fine-tuning more challenging. Our study suggests that, like reasoning and math ability, self-improvement is an emergent property.