 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent On-Line Off-Policy Evaluation
Paper and Code
Feb 23, 2017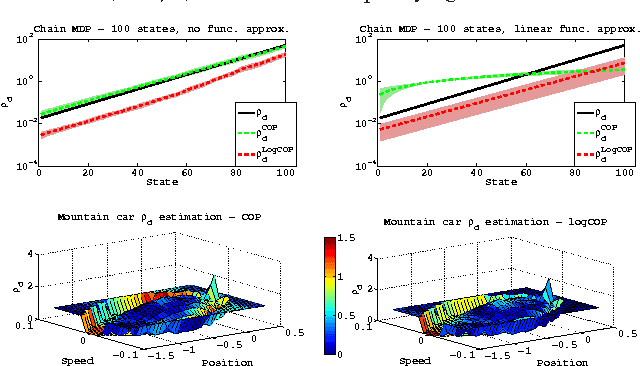

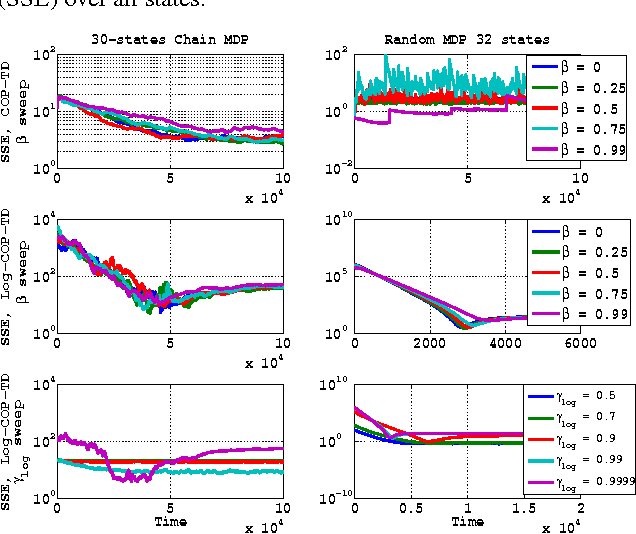

The problem of on-line off-policy evaluation (OPE) has been actively studied in the last decade due to its importance both as a stand-alone problem and as a module in a policy improvement scheme. However, most Temporal Difference (TD) based solutions ignore the discrepancy between the stationary distribution of the behavior and target policies and its effect on the convergence limit when function approximation is applied. In this paper we propose the Consistent Off-Policy Temporal Difference (COP-TD($\lambda$, $\beta$)) algorithm that addresses this issue and reduces this bias at some computational expense. We show that COP-TD($\lambda$, $\beta$) can be designed to converge to the same value that would have been obtained by using on-policy TD($\lambda$) with the target policy. Subsequently, the proposed scheme leads to a related and promising heuristic we call log-COP-TD($\lambda$, $\beta$). Both algorithms have favorable empirical results to the current state of the art on-line OPE algorithms. Finally, our formulation sheds some new light on the recently proposed Emphatic TD learning.