 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformer LLMs -- Convolution Augmented Large Language Models
Paper and Code
Jul 02, 2023
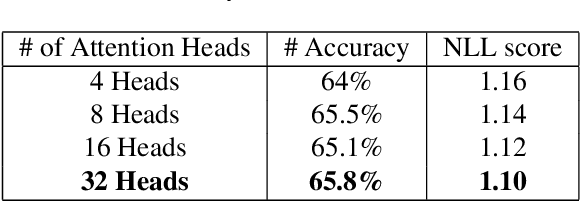
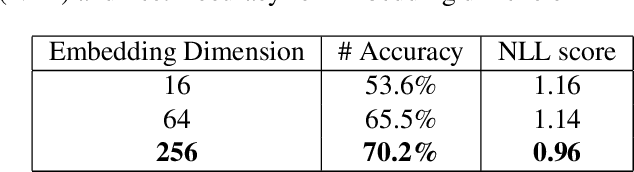

This work builds together two popular blocks of neural architecture, namely convolutional layers and Transformers, for large language models (LLMs). Non-causal conformers are used ubiquitously in automatic speech recognition. This work aims to adapt these architectures in a causal setup for training LLMs. Transformers decoders effectively capture long-range dependencies over several modalities and form a core backbone of modern advancements in machine learning. Convolutional architectures have been popular in extracting features in domains such as raw 1-D signals, speech, and images, to name a few. In this paper, by combining local and global dependencies over latent representations using causal convolutional filters and Transformer, we achieve significant gains in performance. This work showcases a robust speech architecture that can be integrated and adapted in a causal setup beyond speech applications for large-scale language modeling.