 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioning Probabilistic Databases
Paper and Code
Jun 16, 2008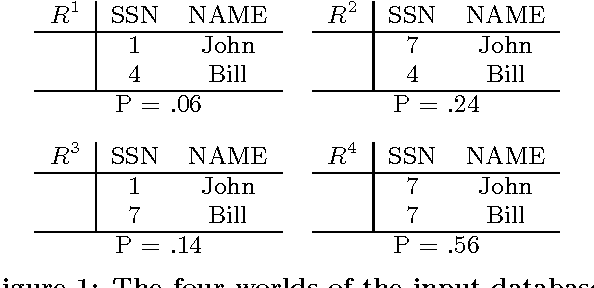
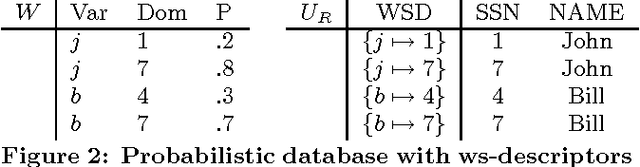
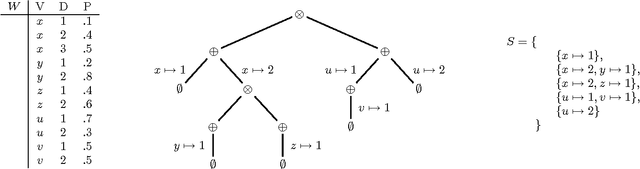

Past research on probabilistic databases has studied the problem of answering queries on a static database. Application scenarios of probabilistic databases however often involve the conditioning of a database using additional information in the form of new evidence. The conditioning problem is thus to transform a probabilistic database of priors into a posterior probabilistic database which is materialized for subsequent query processing or further refinement. It turns out that the conditioning problem is closely related to the problem of computing exact tuple confidence values. It is known that exact confidence computation is an NP-hard problem. This has led researchers to consider approximation techniques for confidence computation. However, neither conditioning nor exact confidence computation can be solved using such techniques. In this paper we present efficient techniques for both problems. We study several problem decomposition methods and heuristics that are based on the most successful search techniques from constraint satisfaction, such as the Davis-Putnam algorithm. We complement this with a thorough experimental evaluation of the algorithms proposed. Our experiments show that our exact algorithms scale well to realistic database sizes and can in some scenarios compete with the most efficient previous approximation algorithms.