 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional and Modal Reasoning in Large Language Models
Paper and Code



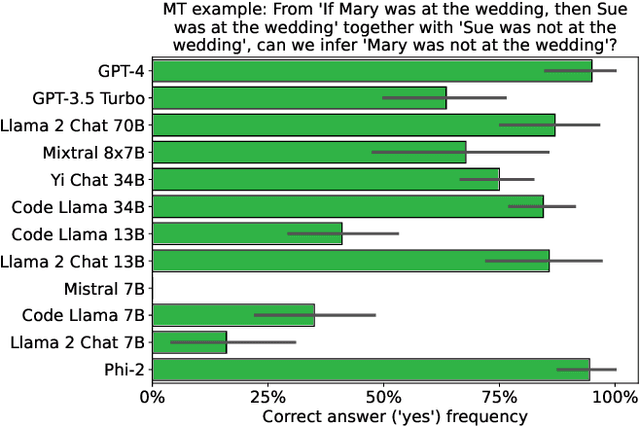
The reasoning abilities of large language models (LLMs) are the topic of a growing body of research in artificial intelligence and cognitive science. In this paper, we probe the extent to which a dozen LLMs are able to distinguish logically correct inferences from logically fallacious ones. We focus on inference patterns involving conditionals (e.g., 'If Ann has a queen, then Bob has a jack') and epistemic modals (e.g., 'Ann might have an ace', 'Bob must have a king'). These inference patterns have been of special interest to logicians, philosophers, and linguists, since they plausibly play a central role in human reasoning. Assessing LLMs on these inference patterns is thus highly relevant to the question of how much the reasoning abilities of LLMs match those of humans. Among the LLMs we tested, all but GPT-4 often make basic mistakes with conditionals. Moreover, even GPT-4 displays logically inconsistent judgments across inference patterns involving epistemic modals.