 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Generalization in Visual Representation Learning
Paper and Code
Dec 10, 2020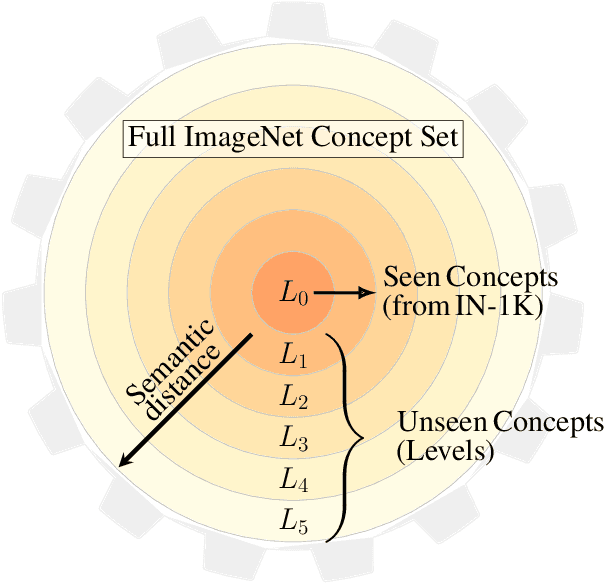
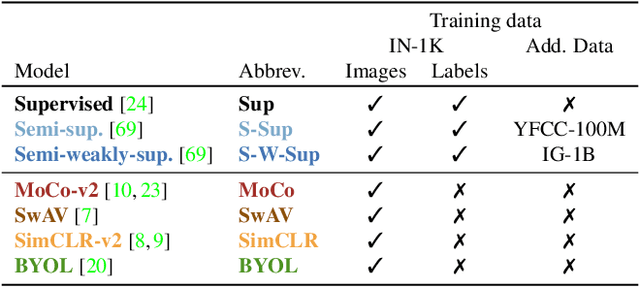
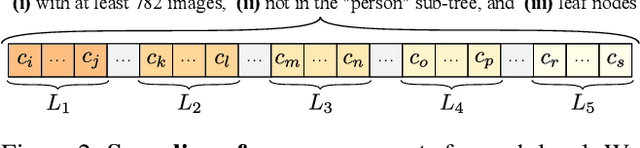
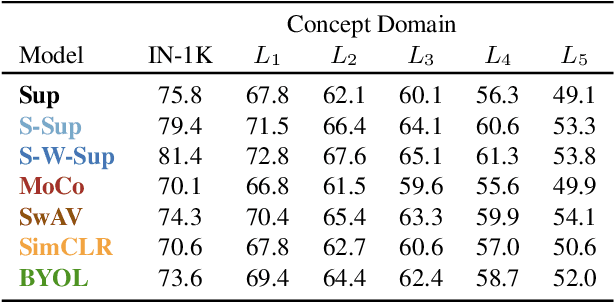
Measuring concept generalization, i.e., the extent to which models trained on a set of (seen) visual concepts can be used to recognize a new set of (unseen) concepts, is a popular way of evaluating visual representations, especially when they are learned with self-supervised learning. Nonetheless, the choice of which unseen concepts to use is usually made arbitrarily, and independently from the seen concepts used to train representations, thus ignoring any semantic relationships between the two. In this paper, we argue that semantic relationships between seen and unseen concepts affect generalization performance and propose ImageNet-CoG, a novel benchmark on the ImageNet dataset that enables measuring concept generalization in a principled way. Our benchmark leverages expert knowledge that comes from WordNet in order to define a sequence of unseen ImageNet concept sets that are semantically more and more distant from the ImageNet-1K subset, a ubiquitous training set. This allows us to benchmark visual representations learned on ImageNet-1K out-of-the box: we analyse a number of such models from supervised, semi-supervised and self-supervised approaches under the prism of concept generalization, and show how our benchmark is able to uncover a number of interesting insights. We will provide resources for the benchmark at https://europe.naverlabs.com/cog-benchmark.