 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing the Value of Data: Towards Applied Data Minimalism
Paper and Code
Jul 29, 2019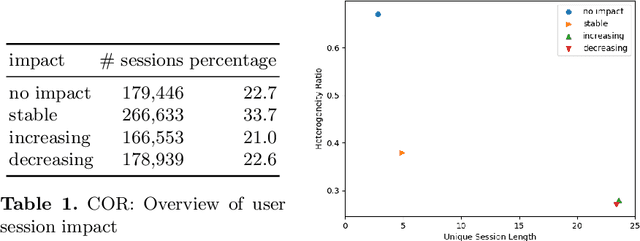
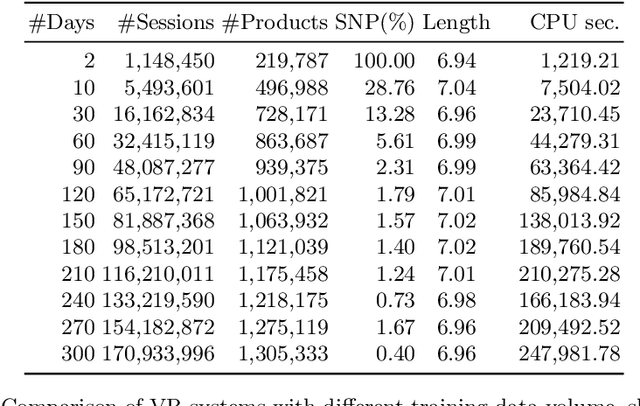
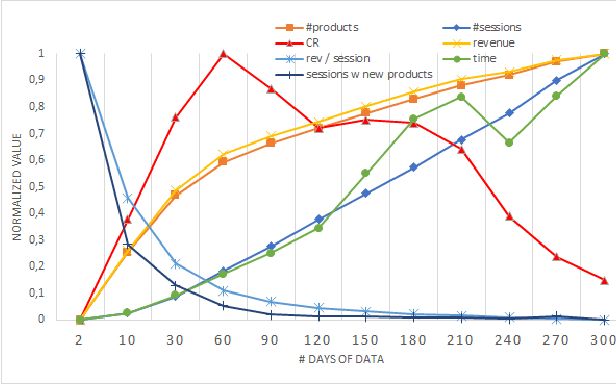
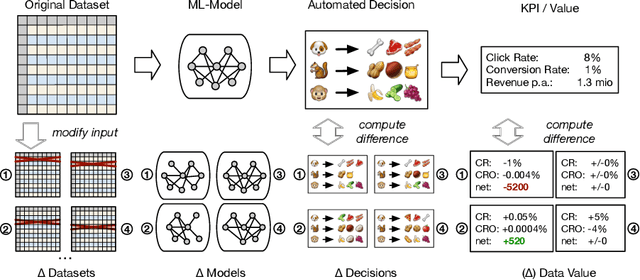
We present an approach to compute the monetary value of individual data points, in context of an automated decision system. The proposed method enables us to explore and implement a paradigm of data minimalism for large-scale machine learning systems. Data minimalistic implementations enhance scalability, while maintaining or even optimizing a system's performance. Using two types of recommender systems, we first demonstrate how much data is ineffective in both settings. We then present a general account of computing data value via sensitivity analysis, and how, in theory, individual data points can be priced according to their informational contribution to automated decisions. We further exemplify this method to lab-scale recommender systems and outline further steps towards commercial data-minimalistic applications.