 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Job Market Analysis with Natural Language Processing
Paper and Code
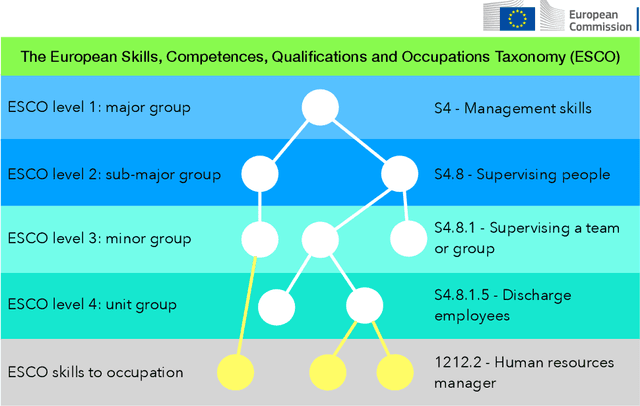
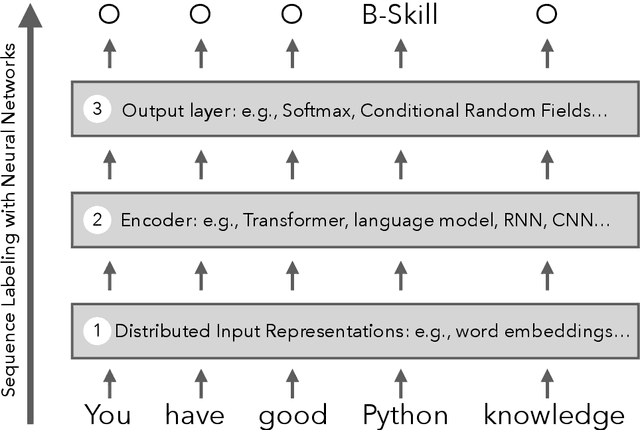
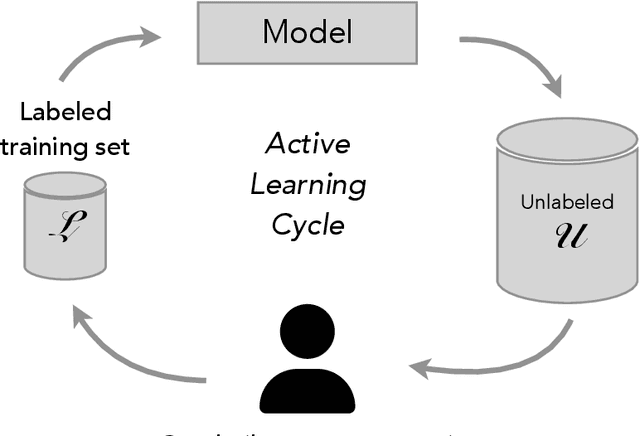

[Abridged Abstract] Recent technological advances underscore labor market dynamics, yielding significant consequences for employment prospects and increasing job vacancy data across platforms and languages. Aggregating such data holds potential for valuable insights into labor market demands, new skills emergence, and facilitating job matching for various stakeholders. However, despite prevalent insights in the private sector, transparent language technology systems and data for this domain are lacking. This thesis investigates Natural Language Processing (NLP) technology for extracting relevant information from job descriptions, identifying challenges including scarcity of training data, lack of standardized annotation guidelines, and shortage of effective extraction methods from job ads. We frame the problem, obtaining annotated data, and introducing extraction methodologies. Our contributions include job description datasets, a de-identification dataset, and a novel active learning algorithm for efficient model training. We propose skill extraction using weak supervision, a taxonomy-aware pre-training methodology adapting multilingual language models to the job market domain, and a retrieval-augmented model leveraging multiple skill extraction datasets to enhance overall performance. Finally, we ground extracted information within a designated taxonomy.