Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressive Learning of Generative Networks
Paper and Code
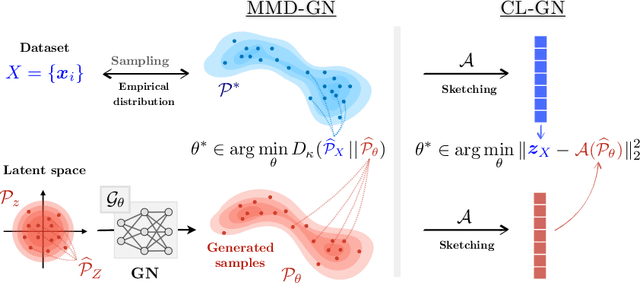

Generative networks implicitly approximate complex densities from their sampling with impressive accuracy. However, because of the enormous scale of modern datasets, this training process is often computationally expensive. We cast generative network training into the recent framework of compressive learning: we reduce the computational burden of large-scale datasets by first harshly compressing them in a single pass as a single sketch vector. We then propose a cost function, which approximates the Maximum Mean Discrepancy metric, but requires only this sketch, which makes it time- and memory-efficient to optimize.
View paper on