 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Heavy-Tailed Weight Matrices for Non-Vacuous Generalization Bounds
Paper and Code
May 23, 2021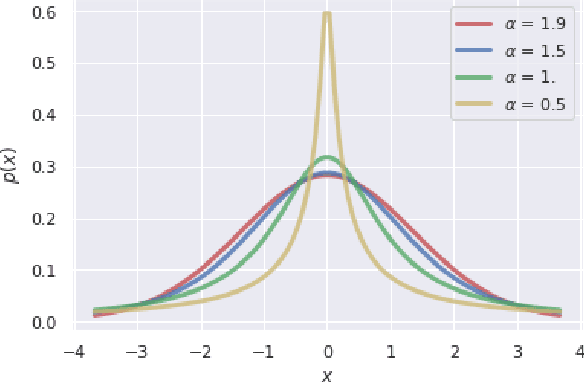
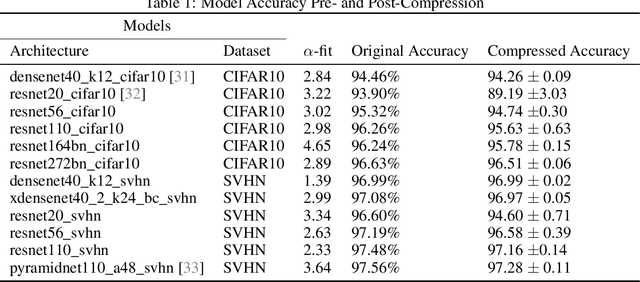
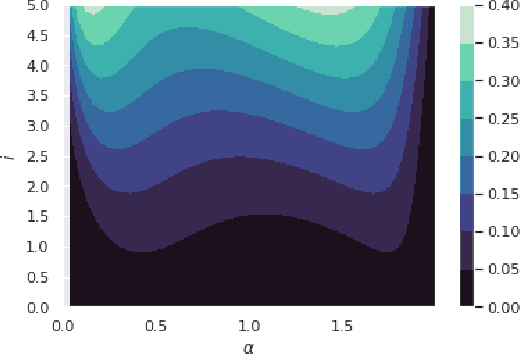
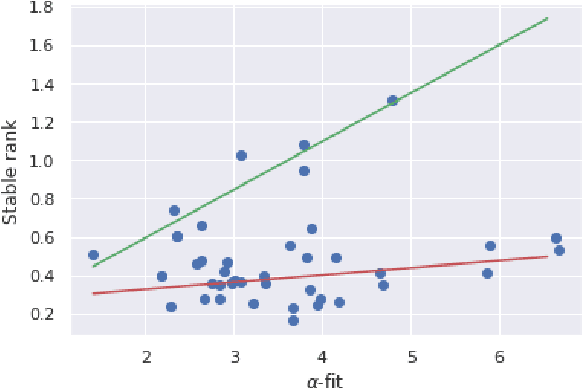
Heavy-tailed distributions have been studied in statistics, random matrix theory, physics, and econometrics as models of correlated systems, among other domains. Further, heavy-tail distributed eigenvalues of the covariance matrix of the weight matrices in neural networks have been shown to empirically correlate with test set accuracy in several works (e.g. arXiv:1901.08276), but a formal relationship between heavy-tail distributed parameters and generalization bounds was yet to be demonstrated. In this work, the compression framework of arXiv:1802.05296 is utilized to show that matrices with heavy-tail distributed matrix elements can be compressed, resulting in networks with sparse weight matrices. Since the parameter count has been reduced to a sum of the non-zero elements of sparse matrices, the compression framework allows us to bound the generalization gap of the resulting compressed network with a non-vacuous generalization bound. Further, the action of these matrices on a vector is discussed, and how they may relate to compression and resilient classification is analyzed.