 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalization for Natural Language Interfaces to Web APIs
Paper and Code
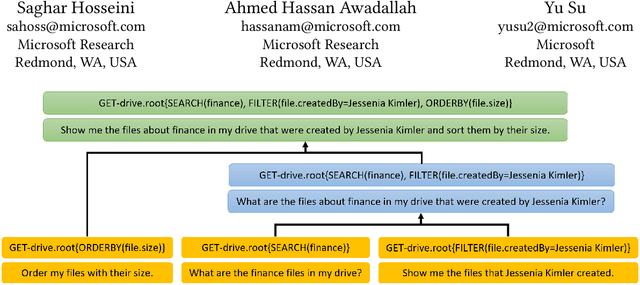


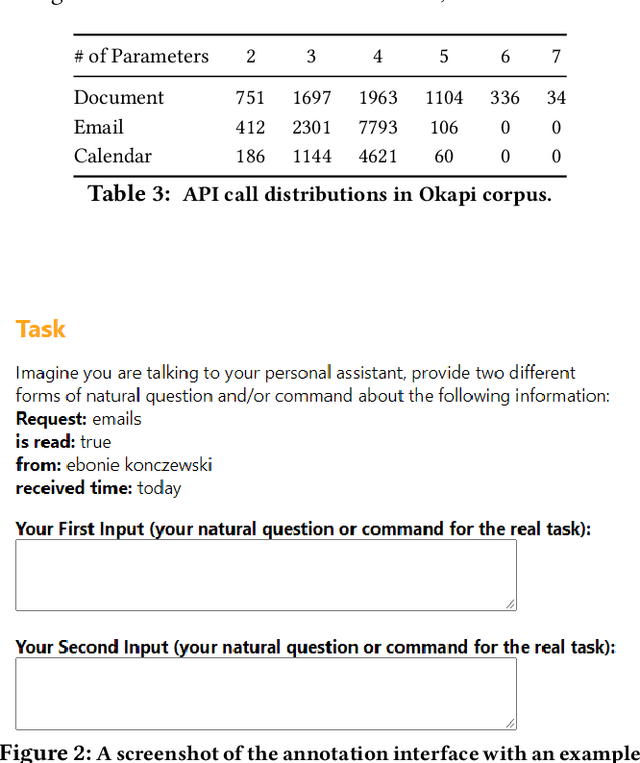
This paper presents Okapi, a new dataset for Natural Language to executable web Application Programming Interfaces (NL2API). This dataset is in English and contains 22,508 questions and 9,019 unique API calls, covering three domains. We define new compositional generalization tasks for NL2API which explore the models' ability to extrapolate from simple API calls in the training set to new and more complex API calls in the inference phase. Also, the models are required to generate API calls that execute correctly as opposed to the existing approaches which evaluate queries with placeholder values. Our dataset is different than most of the existing compositional semantic parsing datasets because it is a non-synthetic dataset studying the compositional generalization in a low-resource setting. Okapi is a step towards creating realistic datasets and benchmarks for studying compositional generalization alongside the existing datasets and tasks. We report the generalization capabilities of sequence-to-sequence baseline models trained on a variety of the SCAN and Okapi datasets tasks. The best model achieves 15\% exact match accuracy when generalizing from simple API calls to more complex API calls. This highlights some challenges for future research. Okapi dataset and tasks are publicly available at https://aka.ms/nl2api/data.