Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex-valued Spatial Autoencoders for Multichannel Speech Enhancement
Paper and Code
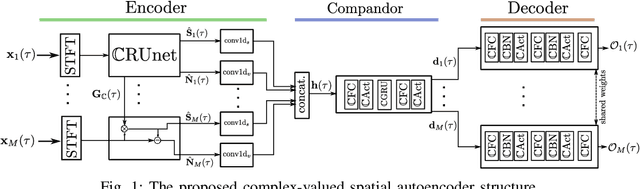
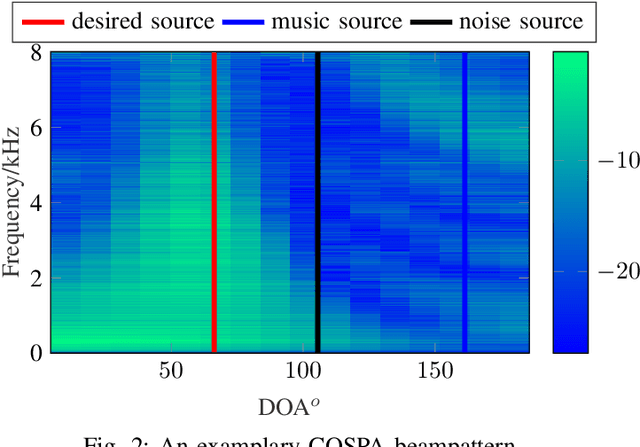
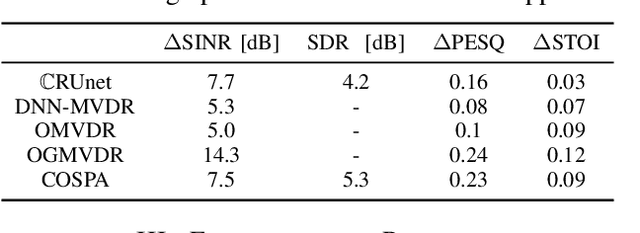
In this contribution, we present a novel online approach to multichannel speech enhancement. The proposed method estimates the enhanced signal through a filter-and-sum framework. More specifically, complex-valued masks are estimated by a deep complex-valued neural network, termed the complex-valued spatial autoencoder. The proposed network is capable of exploiting as well as manipulating both the phase and the amplitude of the microphone signals. As shown by the experimental results, the proposed approach is able to exploit both spatial and spectral characteristics of the desired source signal resulting in a physically plausible spatial selectivity and superior speech quality compared to other baseline methods.
View paper on