 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Transfer Learning based Additive Manufacturing Models via A Case Study
Paper and Code
May 17, 2023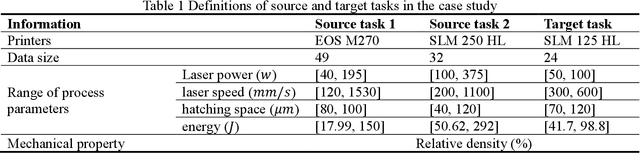
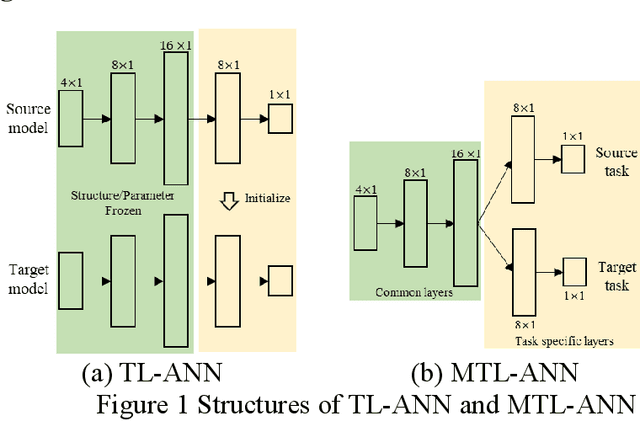

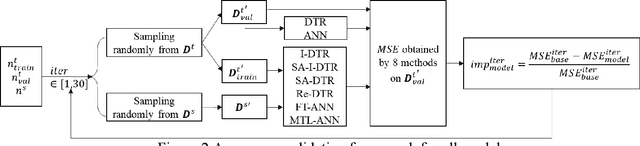
Transfer learning (TL) based additive manufacturing (AM) modeling is an emerging field to reuse the data from historical products and mitigate the data insufficiency in modeling new products. Although some trials have been conducted recently, the inherent challenges of applying TL in AM modeling are seldom discussed, e.g., which source domain to use, how much target data is needed, and whether to apply data preprocessing techniques. This paper aims to answer those questions through a case study defined based on an open-source dataset about metal AM products. In the case study, five TL methods are integrated with decision tree regression (DTR) and artificial neural network (ANN) to construct six TL-based models, whose performances are then compared with the baseline DTR and ANN in a proposed validation framework. The comparisons are used to quantify the performance of applied TL methods and are discussed from the perspective of similarity, training data size, and data preprocessing. Finally, the source AM domain with larger qualitative similarity and a certain range of target-to-source training data size ratio are recommended. Besides, the data preprocessing should be performed carefully to balance the modeling performance and the performance improvement due to TL.