 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of echo state network output layer classification methods on noisy data
Paper and Code
Mar 13, 2017
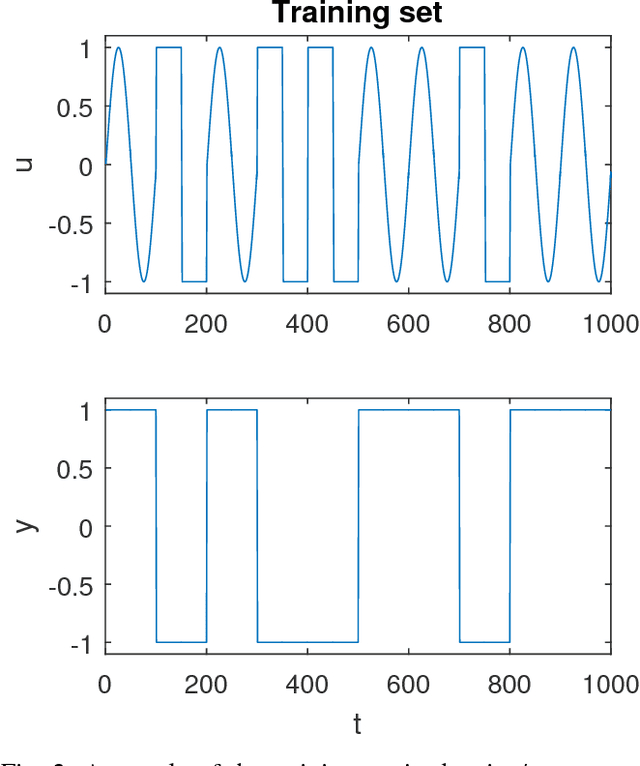
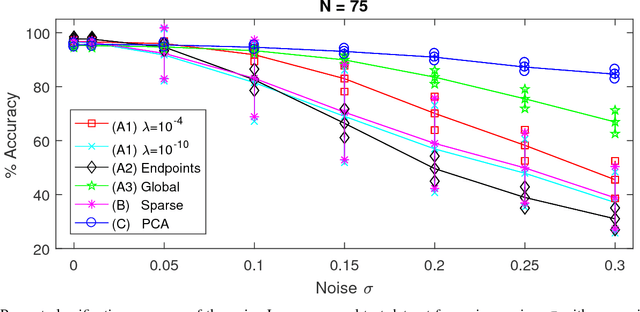
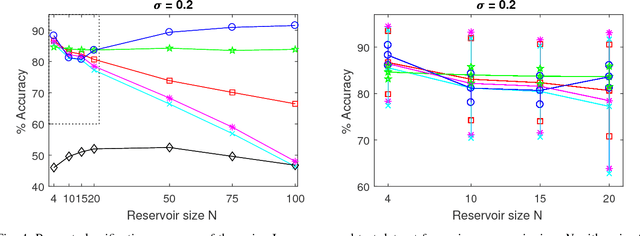
Echo state networks are a recently developed type of recurrent neural network where the internal layer is fixed with random weights, and only the output layer is trained on specific data. Echo state networks are increasingly being used to process spatiotemporal data in real-world settings, including speech recognition, event detection, and robot control. A strength of echo state networks is the simple method used to train the output layer - typically a collection of linear readout weights found using a least squares approach. Although straightforward to train and having a low computational cost to use, this method may not yield acceptable accuracy performance on noisy data. This study compares the performance of three echo state network output layer methods to perform classification on noisy data: using trained linear weights, using sparse trained linear weights, and using trained low-rank approximations of reservoir states. The methods are investigated experimentally on both synthetic and natural datasets. The experiments suggest that using regularized least squares to train linear output weights is superior on data with low noise, but using the low-rank approximations may significantly improve accuracy on datasets contaminated with higher noise levels.