 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Generalization in Learning with Limited Numbers of Exemplars: Transformer vs. RNN in Attractor Dynamics
Paper and Code
Nov 15, 2023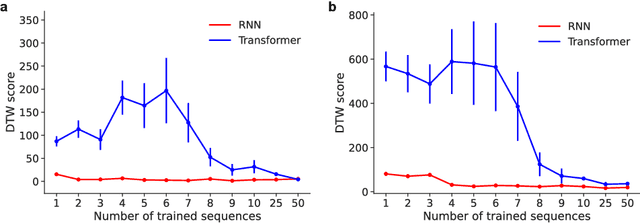
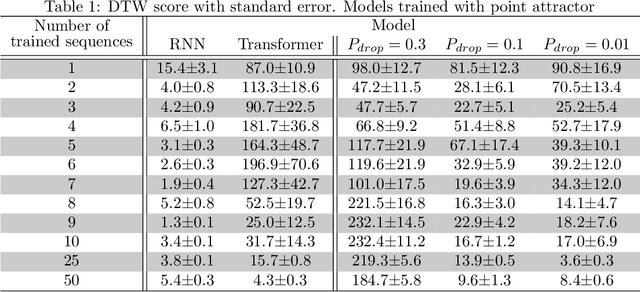
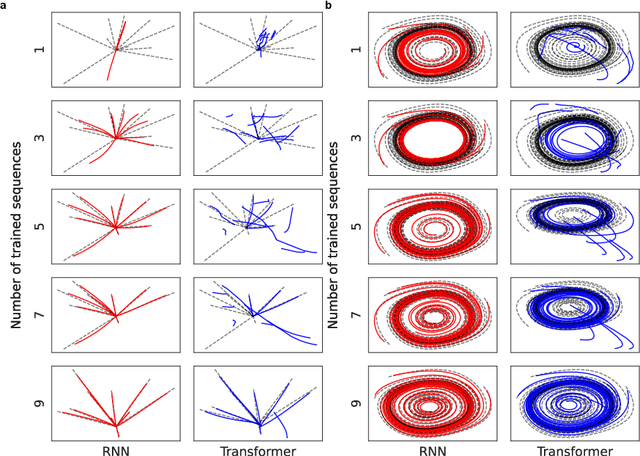
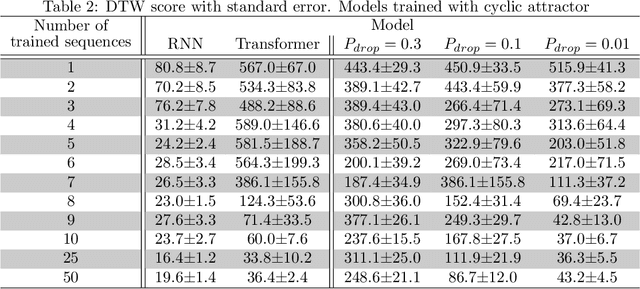
ChatGPT, a widely-recognized large language model (LLM), has recently gained substantial attention for its performance scaling, attributed to the billions of web-sourced natural language sentences used for training. Its underlying architecture, Transformer, has found applications across diverse fields, including video, audio signals, and robotic movement. %The crucial question this raises concerns the Transformer's generalization-in-learning (GIL) capacity. However, this raises a crucial question about Transformer's generalization in learning (GIL) capacity. Is ChatGPT's success chiefly due to the vast dataset used for training, or is there more to the story? To investigate this, we compared Transformer's GIL capabilities with those of a traditional Recurrent Neural Network (RNN) in tasks involving attractor dynamics learning. For performance evaluation, the Dynamic Time Warping (DTW) method has been employed. Our simulation results suggest that under conditions of limited data availability, Transformer's GIL abilities are markedly inferior to those of RNN.