 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity detection using low-dimensional network embedding algorithms
Paper and Code
Nov 04, 2021
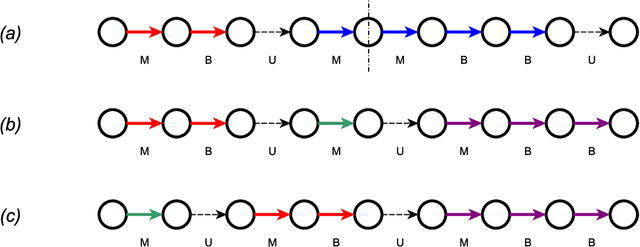
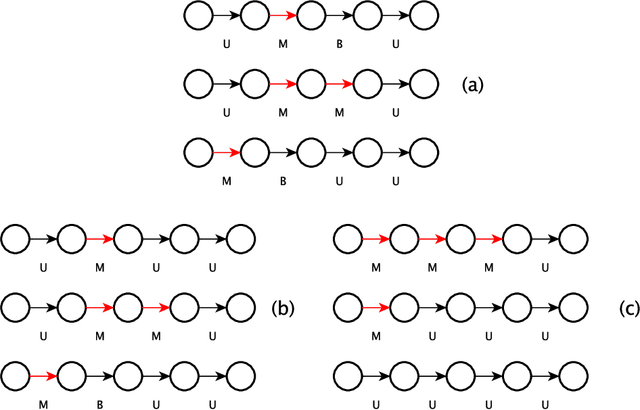
With the increasing relevance of large networks in important areas such as the study of contact networks for spread of disease, or social networks for their impact on geopolitics, it has become necessary to study machine learning tools that are scalable to very large networks, often containing millions of nodes. One major class of such scalable algorithms is known as network representation learning or network embedding. These algorithms try to learn representations of network functionals (e.g.~nodes) by first running multiple random walks and then using the number of co-occurrences of each pair of nodes in observed random walk segments to obtain a low-dimensional representation of nodes on some Euclidean space. The aim of this paper is to rigorously understand the performance of two major algorithms, DeepWalk and node2vec, in recovering communities for canonical network models with ground truth communities. Depending on the sparsity of the graph, we find the length of the random walk segments required such that the corresponding observed co-occurrence window is able to perform almost exact recovery of the underlying community assignments. We prove that, given some fixed co-occurrence window, node2vec using random walks with a low non-backtracking probability can succeed for much sparser networks compared to DeepWalk using simple random walks. Moreover, if the sparsity parameter is low, we provide evidence that these algorithms might not succeed in almost exact recovery. The analysis requires developing general tools for path counting on random networks having an underlying low-rank structure, which are of independent interest.