 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Compression for Decentralized Training
Paper and Code
Sep 27, 2018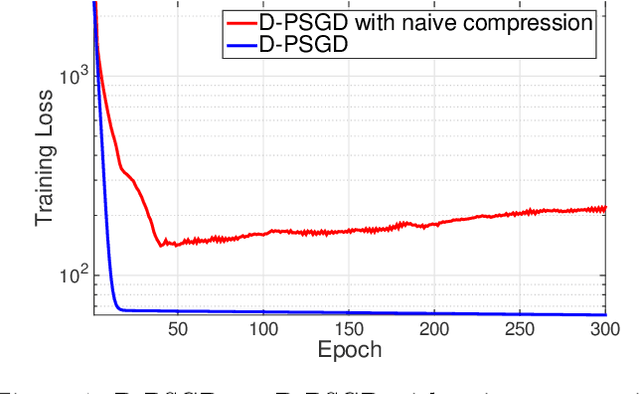
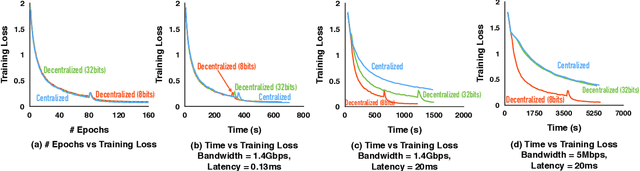
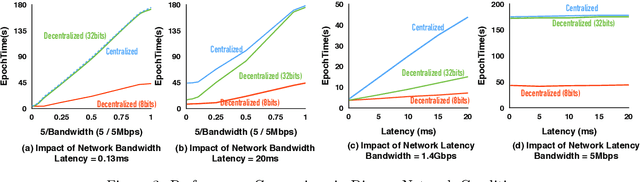
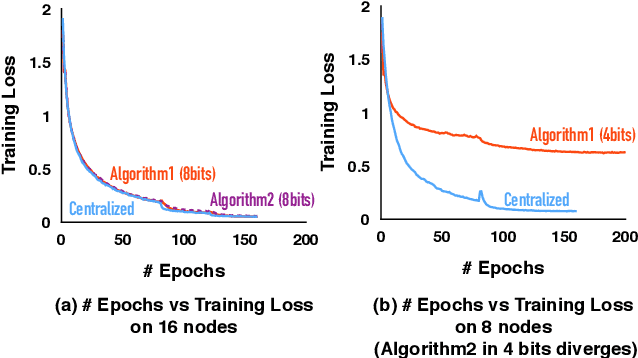
Optimizing distributed learning systems is an art of balancing between computation and communication. There have been two lines of research that try to deal with slower networks: {\em communication compression} for low bandwidth networks, and {\em decentralization} for high latency networks. In this paper, We explore a natural question: {\em can the combination of both techniques lead to a system that is robust to both bandwidth and latency?} Although the system implication of such combination is trivial, the underlying theoretical principle and algorithm design is challenging: unlike centralized algorithms, simply compressing exchanged information, even in an unbiased stochastic way, within the decentralized network would accumulate the error and fail to converge. In this paper, we develop a framework of compressed, decentralized training and propose two different strategies, which we call {\em extrapolation compression} and {\em difference compression}. We analyze both algorithms and prove both converge at the rate of $O(1/\sqrt{nT})$ where $n$ is the number of workers and $T$ is the number of iterations, matching the convergence rate for full precision, centralized training. We validate our algorithms and find that our proposed algorithm outperforms the best of merely decentralized and merely quantized algorithm significantly for networks with {\em both} high latency and low bandwidth.