 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Censored Distributed Stochastic Gradient Descent
Paper and Code

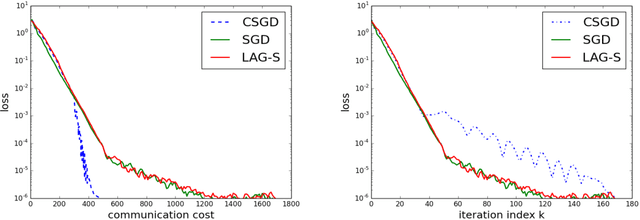
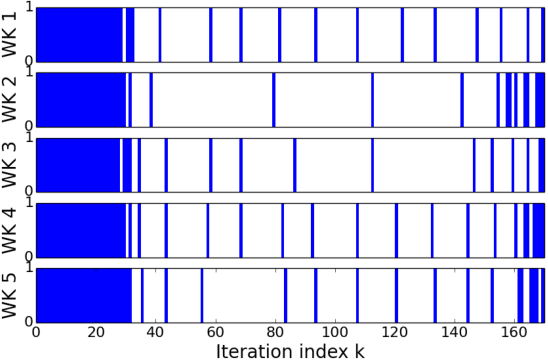
This paper develops a communication-efficient algorithm to solve the stochastic optimization problem defined over a distributed network, aiming at reducing the burdensome communication in applications such as distributed machine learning. Different from the existing works based on quantization and sparsification, we introduce a communication-censoring technique to reduce the transmissions of variables, which leads to our communication-Censored distributed Stochastic Gradient Descent (CSGD) algorithm. Specifically, in CSGD, the latest mini-batch stochastic gradient at a worker will be transmitted to the server only if it is sufficiently informative. When the latest gradient is not available, the stale one will be reused at the server. To implement this communication-censoring strategy, the batch sizes are increasing in order to alleviate the effect of gradient noise. Theoretically, CSGD enjoys the same order of convergence rate as that of SGD, but effectively reduces communication. Numerical experiments further demonstrate the sizable communication saving of CSGD.