 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Learned Lyrical Structures and Vocabulary for Improved Lyric Generation
Paper and Code
Nov 12, 2018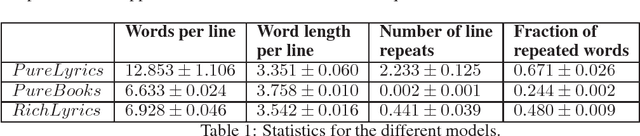
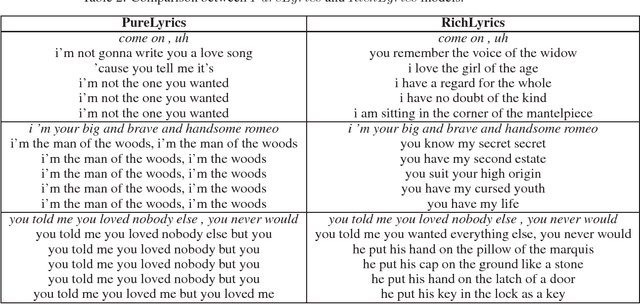
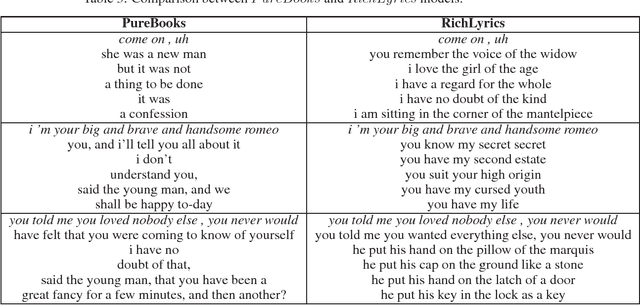
The use of language models for generating lyrics and poetry has received an increased interest in the last few years. They pose a unique challenge relative to standard natural language problems, as their ultimate purpose is reative, notions of accuracy and reproducibility are secondary to notions of lyricism, structure, and diversity. In this creative setting, traditional quantitative measures for natural language problems, such as BLEU scores, prove inadequate: a high-scoring model may either fail to produce output respecting the desired structure (e.g. song verses), be a terribly boring creative companion, or both. In this work we propose a mechanism for combining two separately trained language models into a framework that is able to produce output respecting the desired song structure, while providing a richness and diversity of vocabulary that renders it more creatively appealing.