 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Learning From Distributed Data With Differentially Private Synthetic Twin Data
Paper and Code
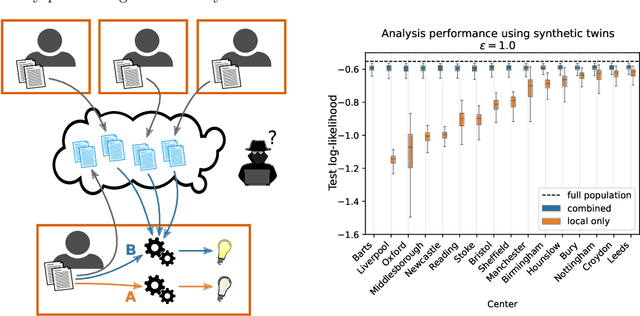

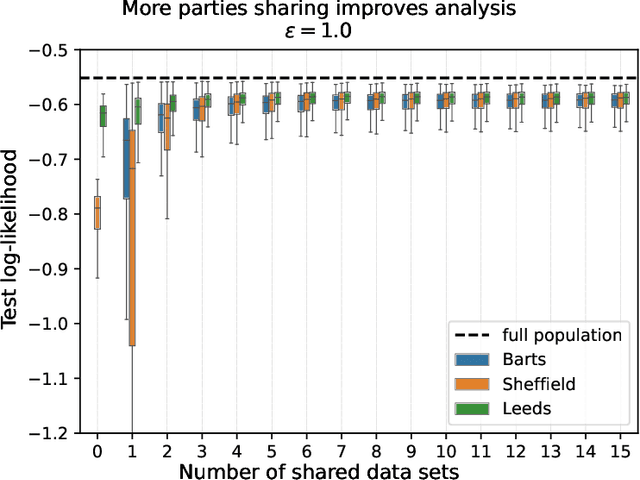
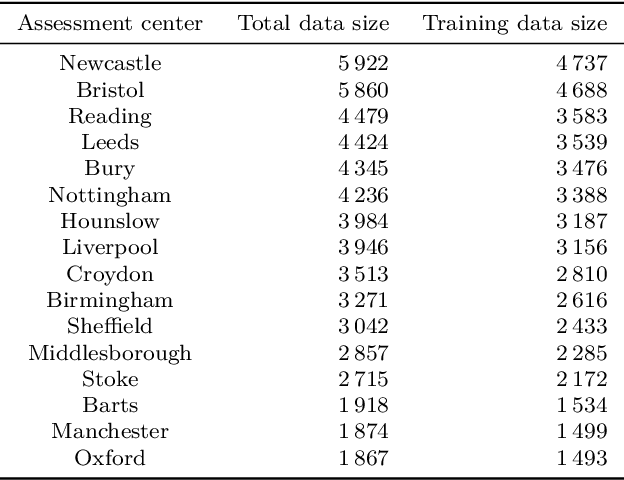
Consider a setting where multiple parties holding sensitive data aim to collaboratively learn population level statistics, but pooling the sensitive data sets is not possible. We propose a framework in which each party shares a differentially private synthetic twin of their data. We study the feasibility of combining such synthetic twin data sets for collaborative learning on real-world health data from the UK Biobank. We discover that parties engaging in the collaborative learning via shared synthetic data obtain more accurate estimates of target statistics compared to using only their local data. This finding extends to the difficult case of small heterogeneous data sets. Furthermore, the more parties participate, the larger and more consistent the improvements become. Finally, we find that data sharing can especially help parties whose data contain underrepresented groups to perform better-adjusted analysis for said groups. Based on our results we conclude that sharing of synthetic twins is a viable method for enabling learning from sensitive data without violating privacy constraints even if individual data sets are small or do not represent the overall population well. The setting of distributed sensitive data is often a bottleneck in biomedical research, which our study shows can be alleviated with privacy-preserving collaborative learning methods.