 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODER: An efficient framework for improving retrieval through COntextualized Document Embedding Reranking
Paper and Code

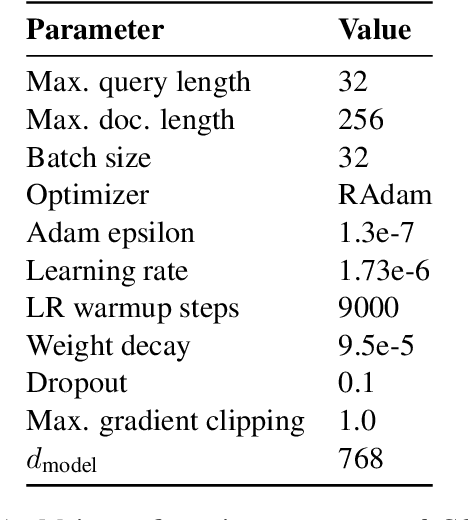
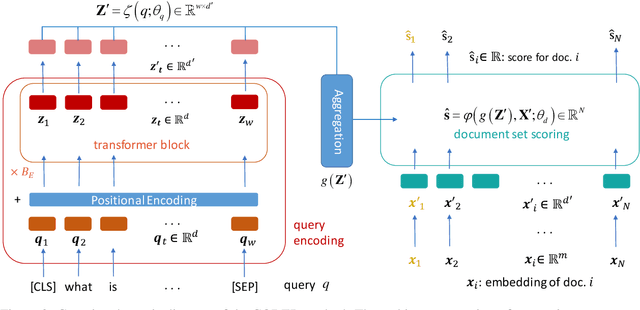
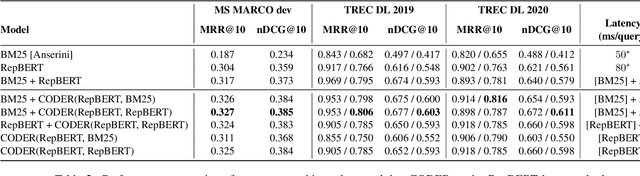
We present a framework for improving the performance of a wide class of retrieval models at minimal computational cost. It utilizes precomputed document representations extracted by a base dense retrieval method and involves training a model to jointly score a large set of retrieved candidate documents for each query, while potentially transforming on the fly the representation of each document in the context of the other candidates as well as the query itself. When scoring a document representation based on its similarity to a query, the model is thus aware of the representation of its "peer" documents. We show that our approach leads to substantial improvement in retrieval performance over the base method and over scoring candidate documents in isolation from one another, as in a pair-wise training setting. Crucially, unlike term-interaction rerankers based on BERT-like encoders, it incurs a negligible computational overhead on top of any first-stage method at run time, allowing it to be easily combined with any state-of-the-art dense retrieval method. Finally, concurrently considering a set of candidate documents for a given query enables additional valuable capabilities in retrieval, such as score calibration and mitigating societal biases in ranking.