 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoded Machine Unlearning
Paper and Code
Dec 31, 2020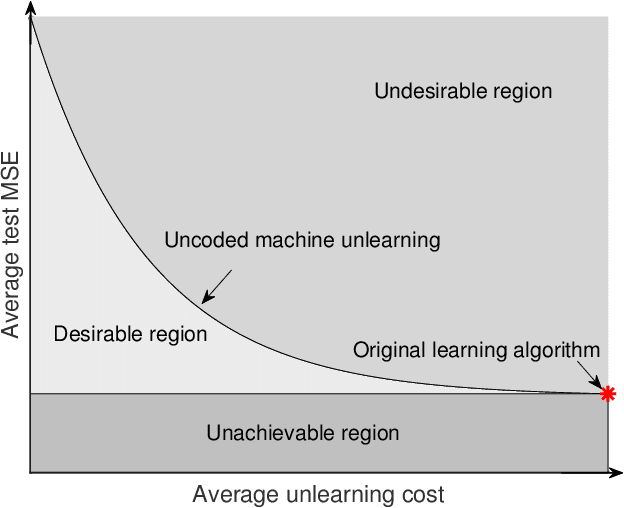
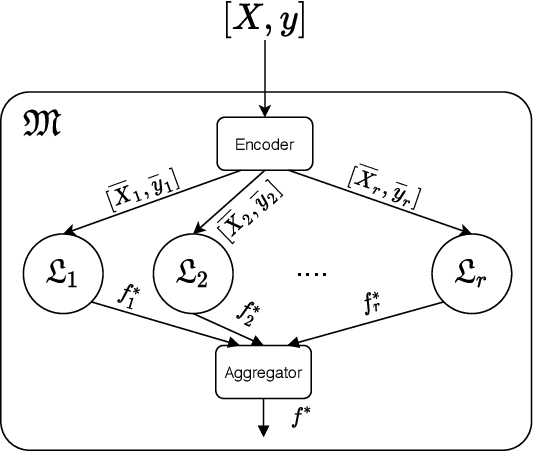
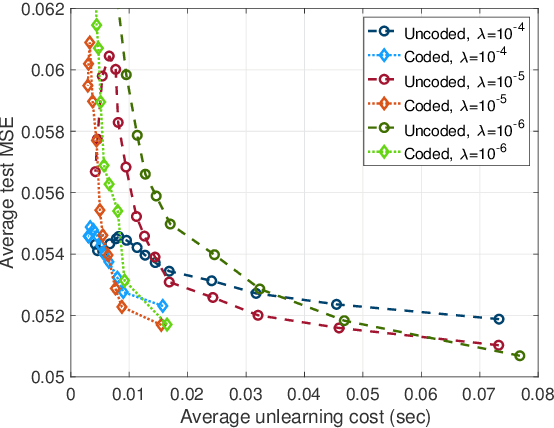
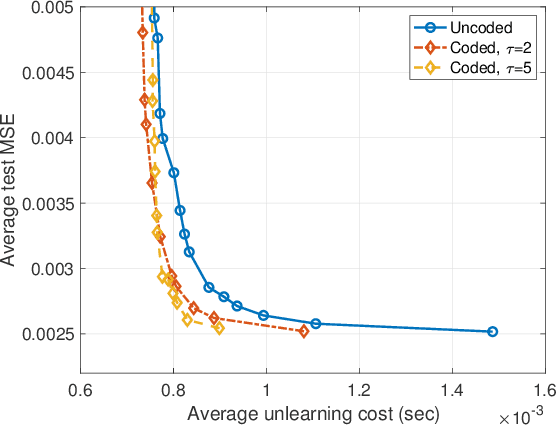
Models trained in machine learning processes may store information about individual samples used in the training process. There are many cases where the impact of an individual sample may need to be deleted and unlearned (i.e., removed) from the model. Retraining the model from scratch after removing a sample from its training set guarantees perfect unlearning, however, it becomes increasingly expensive as the size of training dataset increases. One solution to this issue is utilizing an ensemble learning method that splits the dataset into disjoint shards and assigns them to non-communicating weak learners and then aggregates their models using a pre-defined rule. This framework introduces a trade-off between performance and unlearning cost which may result in an unreasonable performance degradation, especially as the number of shards increases. In this paper, we present a coded learning protocol where the dataset is linearly coded before the learning phase. We also present the corresponding unlearning protocol for the aforementioned coded learning model along with a discussion on the proposed protocol's success in ensuring perfect unlearning. Finally, experimental results show the effectiveness of the coded machine unlearning protocol in terms of performance versus unlearning cost trade-off.